Friday, December 11, 1998
Raszteres grafikus csere formátumok
Ebben a részben néhány
- általános kérdés áttekintése után
- a TIFF,
- a GeoTIFF,
- az ERDAS Imagine és
- az Idrisi raszteres formátumokat ismerjük meg.
A raszteres adatmodell legfontosabb kérdéseivel viszonylag részletesen foglalkoztunk a 7 és 9 lapokon, igaz, hogy az egyszerűbb megértés kedvéért a fogalmakat kétértékű, bináris képeken mutattuk be. Később azonban több helyen (pld a 21 vagy 22 lapokon) részletesen megismerkedtünk a tónusos, színes, multispektrális képek legfőbb jellemzőivel illetve a velük végezhető műveletekkel.
A raszteres adatmodell ezek szerint nem más, mint szabályos rácsba szervezett négyzetes képelemek (pixelek) értékeinek mátrixa.
Ez az egyszerű struktúra négy ok miatt eredményez számtalan formátumot. Az egyik ok az, hogy milyen értékeket vehetnek fel a pixelek, a másik hogy milyen tömörítési eljárást alkalmazunk, a harmadik, hogy a pixelek elrendezését (hány pixel van egy sorban és hány sor van a képben), illetve a kép általános adatait hogyan adjuk meg, végül a formátumok különböznek a kódolás típusa szerint is. Tekintsük át ezeket az okokat egyenként:
- Bináris képek (és bináris kódolás) esetén minden pixelnek egy bitet kell fenntartanunk. Tónusos fekete-fehér képek esetén 256 szürkeségi fokozatot szoktak alkalmazni, ami 8 bittel írható le, színes képek esetén számtalan variáció létezik a biztosítandó színgazdagságra: pld. 24 bit esetén 16 millió különféle színt lehet a pixelekhez rendelni, a multispektrális távérzékelt képeknél gyakorlatilag az érzékelt csatornák számának megfelelő számú képet kell egyszerre rögzíteni, amit vagy úgy csinálnak, hogy minden pixelnél egymásután rögzítik a különböző csatornák intenzitás értékeit, azaz 4 csatorna és 256 intenzitás fokozat esetén minden pixelt 32 biten rögzítenek, vagy a sorokat fűzik egymásután vagy a spektrális képeket. A GIS fedvény esetén azonban elvileg nem színeket hanem valamilyen tulajdonságjellemző értéket kell a pixelekhez rendelni, az pedig igen erősen szoftver függő, hogy milyen jellegű (fixpontos előjeles, lebegőpontos előjeles, szöveges, stb.) érték milyen tartománya rendelhető a pixelhez. Ha térinformatikai állományt akarunk átvinni, akkor azt is valamilyen formában közölni kell, hogy az átvitt értékek mit jelentenek.
- Számtalan tömörítési eljárás elvével ismerkedtünk meg a 7 lapon. A tényleges tömörítést azonban ezek és más, eddig nem ismertetett, elvek alapján működő konkrét algoritmusok valósítják meg, következésképpen minden formátumhoz specifikált tömörítő algoritmus vagy algoritmusok tartoznak, ez utóbbi esetben az átvitt fájlban specifikálni kell a konkrét algoritmust is.
- Nem földrajzi adatok (egyszerű képek) esetén általában a fájl fejezete tartalmazza az oszlopok és sorok számát, a verzió számot a színek számát és a tömörítési módszer kódját. Földrajzi adatok esetén azonban még sok egyéb adatra is szükség van. Ilyen mindenek előtt a georeferencia azaz a 'kép' sarokpontjainak koordinátái valamely vetületi rendszerben, a pixel értékek jelentése, és a 'kép' gyártására, elhelyezkedésére, pontosságára, stb. vonatkozó metaadatok. Mivel a földrajzi adatok nélküli 'kép' a számtalan képi formátum (GIF, TIFF, JPEG, BMP, stb.) bármelyikében továbbítható, feltéve, hogy a pixelértékek kielégítik a kérdéses formátum specifikációját, a GIS rendszerek gyakran élnek azzal a lehetőséggel, hogy a 'földrajzi fejezetet' külön fájl formájában viszik át illetve kezelik.
- A kódolás vagy bináris vagy szöveges (ASCII) lehet, s amint azt már az 5.1 táblázatban több helyen is láttuk, ugyanaz a formátum gyakran mind a két kódolási formát ismeri.
Mivel nem célunk az általános rendeltetésű kép formátumok ismertetése megpróbálunk kissé részletesebben egy olyan formátumot ismertetni, melyet egy általános képi formátum a TIFF (ha rákattintunk a linkre letölthetjük a TIFF6 specifikációt angolul pdf formátumban) még kötetlen specifikációs lehetőségeinek felhasználásával direkt földrajzi információ, konkréten szkennelt topográfiai térképek átvitelére fejlesztett ki a USGS. Ez a formátum a GeoTIFF . Ahhoz azonban, hogy ezt a formátum bővítést megértsük meg kell röviden ismernünk az eredeti formátumot is.
A TIFF formátum
A TIFF (Tagged-Image File Format, azaz címkézett kép fájl formátum) formátumot az Aldus cég fejlesztette ki a nyolcvanas évek végén, majd miután egyesült az ADOBE céggel a formátum fejlesztését az ADOBE keretein belül folytatta. A jelenleg érvényes legújabb specifikáció az 1992-ben kiadott 6-os verzió. A specifikáció nyilvános (public domain), tehát bárki ingyenesen felhasználhatja TIFF író és olvasó programok fejlesztésére.
|
|
5.2 ábra a TIFF fájl szerkezete |
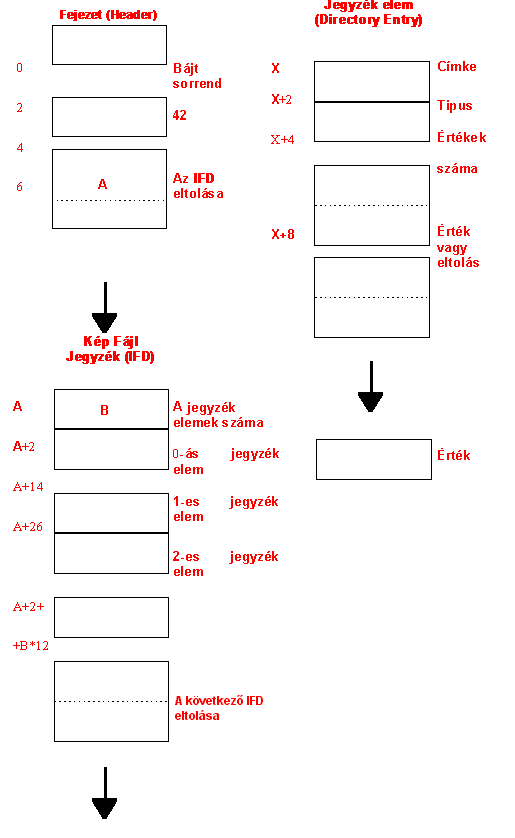
Az 5.2 ábrán felvázoltuk a TIFF fájl szerkezetét. A fájl elején található fejezet (header) tulajdonképpen csak az összetett fejezet bevezető része. Az első két bájt (0,1) a bájtok tárolási sorrendjét határozza meg mind a 16 bites mind a 32 bites egész számok esetére, ha ez az érték 'II', akkor a bájtok helyértéke a tárolásban jobbról balra csökken, 'MM' esetén pedig a megszokott módon balról jobbra.
A 2-3 bájtok egy tetszőlegesen de gondosan megválasztott számot (42) tartalmaznak, mely a fájlt TIFF fájlként azonosítja. A 4-7 bájtok az összetett fejezet második, lényegi részének az első Kép Fájl Jegyzéknek (Image File Directory=IFD) az eltolási értékét adják meg bájtban. A fájlban több IFD is lehet, és fájlon belüli elhelyezkedésük nem kötött. Az eltolási érték tulajdonképpen az IFD első bájtjának sorszáma. Ez mindig szóhatárra esik azaz páros szám. Legalább egy IFD kell a TIFF fájlba és minden IFD-nek legalább egy eleme (Entry) kell, hogy legyen.
Az IFD elemek 12 bájt hosszúak és felépítésük a következő:
- 0-1 bájt - a mezőazonosító címke;
- 2-3 bájt - a
mezőtípus az alábbi kódokkal:
1=BYTE
2=ASCII
3=SHORT
4=LONG
5=RATIONAL (két LONG, az első a számláló, második a nevező)
12=DOUBLE (8 bájton ábrázolt kettős pontosságú valós szám); - 4-7 bájt - az értékek száma a megadott mezőtípusban kifejezve;
- 8-11 bájt - az érték eltolása, azaz a címke értéke első bájtjának sorszáma, mely mindig páros szám.
A felvázolt struktúra alapján közvetlenül belátható, hogy a TIFF igen rugalmas formátum, mivel a tárolt információ milyensége rugalmasan bővíthető címkék segítségével vezérelhető. A hagyományos raszteres GIS formátumokban a fejezet, illetve a fejezet szerepét játszó külön fájl általában rögzített elemeket tartalmaz, melyek jellege és értéke rendszerint nem bővíthető. A TIFF esetében egy alapcímke halmazt minden író és olvasó programnak értelmeznie kell, e mellett, mind a specifikáció gondozói, mind a felhasználók kiegészíthetik a rendszert úgy nevezett bővítésekkel illetve privát címkékkel. A privát címkék 32768 sorszámmal kezdődhetnek.
Hogy valamilyen elképzelésünk is legyen a címkék milyenségéről bemutatunk néhányat az alapcímkék közül, mégpedig a TIFF által kezelt négy, fekete-fehér, szürkeségi érték, paletta szín és teljes szín alap képtípusra vonatkoztatva.
A bináris képek esetén
- a színmeghatározó (PhotometricInterpretation) címke sorszáma: 262, tipusa: SHORT (16 bites előjel nélküli egész), értéke 0 (a zérus fehér) vagy 1 (a zérus fekete).
- a tömörítés (Compression) címke sorszáma 259, tipusa SHORT, értéke 1 ha nincs tömörítés csak úgynevezett 'csomagolás' (erre vonatkozó részletek is találhatók a verzió specifikációban [3]), illetve 2 a sorkifejtő kódolás (run-length encoding) (lsd. 2.2.2.1.) alkalmazása esetén, vagy 32773 a sorkifejtő kódolás egy bájt orientált verziója (PackBit compression) alkalmazása esetén.
- a képhossz (ImageLength) címke sorszáma 257, típusa SHORT vagy LONG (32 bit előjel nélküli egész), értéke a sorok száma.
- a kép szélesség (ImageWidth) címke sorszáma 256, típusa SHORT vagy LONG, értéke a soronkénti pixelek száma.
- a felbontási mértékegység (ResolutionUnit) címke sorszáma 296, típusa SHORT, értéke 1 ha nincs abszolút mértékegység, 2 inch, 3 centiméter.
- az X irányú felbontás (XResolution) címke sorszáma 282, típusa RATIONAL (két LONG az első a tört számlálója, második a nevezője), értéke a felbontási mértékegységre eső soronkénti pixelek száma.
- az Y irányú felbontás (YResolution) címke sorszáma 283, típusa RATIONAL, értéke a felbontási mértékegységre eső oszloponkénti pixelek száma.
- a csíkonkénti sorok száma (RowsPerStrip) címke sorszáma 278, típusa SHORT vagy LONG, értéke a csíkokban lévő sorok száma (mivel az összes sor számát a képhossz címke értéke már megadta, ez a címke megadja a csíkok számát is, ha a képhossz nem többszöröse, úgy az utolsó csík sorszáma eltérő lesz).
- a csíkeltolás (StripOffsets) címke sorszáma 273, típusa SHORT vagy LONG, értéke minden csíkra megadja a kezdő bájt sorszámát.
- a csíkonkénti bájtok száma (StripByteCounts) címke sorszáma 279, tipusa SHORT vagy LONG, értéke minden csíkra megadja a tömörítés utáni bájtok számát.
Paletta színes képek esetén a következő módosulások álnak elő:
- a színmeghatározó címke értéke 3.
- új kötelező címke a színtérkép (ColorMAP) címke, sorszáma 320, típusa SHORT, értéke N = 3*2(mintánkénti bitek).
Végül teljes RGB színes képek esetén a paletta színes képhez képest a következő módosulások lépnek fel:
- nincs színtérkép;
- a mintánkénti bitek címke értéke 8,8,8.
- a színmeghatározó címke értéke 2.
- Új, pixelenkénti minták (SamplesPerPixel) címke sorszáma 277, típusa SHORT, értéke, ha nem rendelkezünk extra mintákkal, 3.
A GeoTIFF formátum
Az eddigiek alapján érthető, hogy miért kötődtek a TIFF formátumhoz azok a szakterületek, melyek az elvileg tetszőleges pixeltartalmú raszteres képeket hardver és szoftver független módon akarták átvinni az egyik rendszerből a másik rendszerbe.
Ahhoz azonban, hogy a földrajzi vonatkozások is együtt kerüljenek átvitelre a képi anyaggal ki kellett dolgozni azokat a címkéket, melyek lehetővé teszik a georeferenciát, az objektum osztályozást, a metaadatok átvitelét, stb.
Ezt a munkát a 90-es évek elején kezdték meg az Intergraph-nál, 1994-ben Niles Ritter a Jet Propulsion Laboratory (JPL) munkatársa levelező csoportot szervezett a témában, majd 1995 márciusában konferenciát hívtak össze a SPOT Image, USGS, Intergraph, ESRI, ERDAS, SoftDesk, MapInfo, NASA/JPL, és más cégek és intézmények képviselőinek részvételével, mely elviekben elfogadta a GEOTIFF specifikációt. A specifikációt végleges formába Niles Ritter, és Mike Ruth öntötték.
Ahhoz tehát, hogy a TIFF formátum földrajzi vonatkozásokkal bővüljön ez utóbbiakra privát címkékkel kell utalni. Mivel azonban a földrajzi vonatkozásokban óriási számú vetületi paraméter is szerepel, nagyon sok privát címkét kellene lefoglalni, ami egyrészt azért káros, mivel szűkíti az egyéb alkalmazásokra felhasználható címkék körét, másrészt lelassítja a TIFF kép értelmezését olyan olvasókkal, melyek nem ismerik a GeoTIFF specifikációt. A GeoTIFF képet ugyanis szemlélhetjük közönséges képként is olyan olvasóval, mely figyelmen kívül hagyja a földrajzi címkéket. Az ilyen olvasó azonban megpróbálja értelmezni az összes IFD-t, mivel az eltolásokból nem derül ki, hogy privát vagy alap IFD-ről van e szó és ezzel nagyon sok időt pazarol.
A fenti hátrányok csökkentése érdekében a nagyszámú privát címke helyett egy privát címkével azonosított kulcsokat (geoKeys) használ a GeoTIFF, ami tulajdonképpen azt jelenti, hogy az eredeti TIFF-be hierarchikusan beillesztünk egy olyan címke funkciójú kulcsrendszert, melyet a GeoTIFF olvasók egy privát címkén keresztül érhetnek el, míg az egyszerű olvasók ezen a címkén átugranak. A funkció tekintetében a kulcsok annyiban különböznek a címkéktől, hogy az előbbiek a formattált címkék típusú értékekre hatnak olyanképpen mint a címke értékek a nyers adatbájtokra.
A címkékhez hasonlóan minden kulcsnak van egy 0-tól 65535-ig terjedhető azonosítója, mely azonban a címkéktől eltérően szabadon használható a GeoTIFF földrajzi paraméter definíciós céljaira.
Valamennyi kulcsot a GeoKulcsKönyvtárCímkén (GeoKeyDirectoryTag) keresztül éri el az olvasó program. Lássuk a legfontosabb adatait:
Név: GeoKeyDirectoryTag
címke azonosító = 34735 (87AF.H)
típus = SHORT (2-bájtos előjel nélküli short)
N = változó, >= 4
más nevei: ProjectionInfoTag, CoordSystemInfoTag
tulajdonos: SPOT Image, Inc.
A címke értékét négyesével csoportosított előjel nélküli rövid egész számok alkotják. Az első négyes csoportot a könyvtár fejezete képezi, mely a következő értékekből áll:
KulcsKönyvtárVerzió (KeyDirectoryVersion) a
jelenlegi verzió esetében 1;
KulcsFőRevízióSzám (KeyRevision) egyelőre 1;
KulcsAlRevízióSzám (MinorRevision) jelenleg 2;
KulcsokSzáma (NumberOfKeys) hány kulcsot tartalmaznak a címke
további blokkja(i).
A fejezet után következnek a KulcsokSzámában megadott számú, 4 SHORT hosszú kulcselem együttesek (KeyEntry sets), melyeket az 5.2 ábrán bemutatott 'JegyzékElem' formátumnak megfelelő formátumban modelleznek. Ez gyakorlatilag azt jelenti, hogy minden kulcs első rövid egész értéke a kulcs kódja, utána következik a típusa, mely 0 értéket kap, ha SHORT, privát címke azonosítót kap, ha kettős pontosságú (34736) vagy szöveges (34737). Maga az érték az első esetben a négyes blokk utolsó elemébe kerül. A második illetve harmadik esetben az érték a kérdéses címkéhez kapcsolódik, azt pedig, hogy a kérdéses címke hol van a blokk negyedik eleme tartalmazza. A négyes blokk harmadik eleme az értékek számát tartalmazza.
Amint már utaltunk rá, ha a kulcs értéke nem rövid egész típusú, úgy azt két újabb privát címkével azonosított típusban kell tárolni. Ezek a címkék a következők:
Név: GeoAsciiParamsTag
címke azonosító = 34737(87B1.H)
típus = ASCII(szöveg)
N = változó
tulajdonos: SPOT Image, Inc.
Név: GeoDoubleParamsTag
címke azonosító = 34736(87B0.H)
típus = DOUBLE (IEEE kettős pontosságú lebegőpontos)
N = variable
tulajdonos: Spot Image, Inc.
Lássunk ezután egy egyszerű példát, melyet a GeoTIFF specifikációból kölcsönöztünk esetenként javítva a nyilvánvaló hibákat
|
GeoKeyDirectoryTag(34735)=( |
|
||||||||||||||||||||||||||||
|
GeoDoubleParamsTag(34736)=( |
1.5) |
||||||||||||||||||||||||||||
|
GeoAsciiParamsTag(34737)=( |
"Custom File|My Geographic|") |
A példa elemzése előtt meg kell jegyeznünk, hogy a GeoTIFF író
program a GeoKulcsKönyvtárCímke értékeit azaz a geokulcs
azonosítókat ugyanúgy sorba rakja ahogy a TIFF igényeinek megfelelően maguk a
címke azonosítók is rendezésre kerülnek.
Az első sorból azt látjuk. Hogy a GeoTIFF földrajzi kulcs könyvtárának 1-es
verzióját, annak is 1.2-es változatát használjuk és 6 földrajzi kulcsra
hivatkozunk.
A második sor az 1024-es sorszámú földrajzi kulcsra hivatkozik, mely a használt koordináta rendszer típusát specifikálja (GTModelTypeGeoKey). A 2 érték a földrajzi koordináta rendszer típusnak felel meg. Az érték maga a lista negyedik helyén helyezkedik el, mivel a második elem értéke 0.
A harmadik sor az 1026 sorszámú GTCitationGeoKey elnevezésű, szöveges idézet értékű földrajzi kulcsra hivatkozik. Minden Citation (Idézet) jellegű kulcs a TIFF fájl átfogó szöveges jellemzésére szolgál. Mivel ezek típusa ASCII ézért értékük nem helyezkedhet el közvetlenül a kulcs blokkban, hanem csak az e típust deklaráló GeoAsciiParamsTag(34737) nevű és sorszámú privát címke jegyzékében. Mivel a harmadik sor negyedik eleme 0, a szöveg eltolás nélkül közvetlenül a címke sorszáma után következik 12 bájt hosszban (mivel a sor harmadik száma 12) és értéke ezek szerint Custom File ( a | elválasztó karaktert az olvasó program zérussá alakítja).
A 2048 sorszámú, GeographicTypeGeoKey elnevezésű kulcs azt mondja meg, hogy a szélesség-hosszúság (j, l) rendezőjű földrajzi koordináta rendszer milyen ellipszoidra vonatkozik és hogy milyen ezen az ellipszoidon a kezdő meridián felvétele. Számtalan variációt kódolnak a kulcs értékekkel, a példánkban szereplő 32767 érték a felhasználó által meghatározott rendszer kódja. Mivel a sorban második szám 0, a harmadik pedig 1, az érték a kérdéses sor negyedik rövid egész száma azaz 32767.
Az ötödik sorban szereplő 2049 sorszámú GeogCitationGeoKey elnevezésű kulcs az összes földrajzi koordináta rendszer paraméterre vonatkozó általános hivatkozásokra, idézetekre utal. Mivel ezek is ASCII típusúak, ezért a kérdéses szövegek (azaz a kulcs értékei) a már bemutatott GeoAsciiParamsTag(34737) tipus deklaráló címke tömbjébe kerülnek tárolásra. Azaz mivel a sor második száma 34737 az olvasó program megkeresi a kérdéses címkét, a negyedik számnak megfelelően leszámlál 12 bájt eltolást (itt helyezkedett el a korábbi szövegünk) majd az itt kezdődő és 14 bájt hosszú szöveget ami My Geographic| azonosítja a kulcs által hivatkozott idézettel. Amint már utaltunk rá a | jelet az olvasó programok nullázzák.
A következő sorban található 2050 sorszámú GeogGeodeticDatumGeoKey elnevezésű földrajzi kulcs a geodéziai dátumot határozza meg a felhasználó által definiált koordináta rendszerhez. Mivel a sor második száma 0, harmadik száma pedig 1 a kulcs értékét, ami tulajdonképpen egy kód, a sor utolsó száma tartalmazza. Az esetünkben szereplő 6237 kód a HD-72 elnevezésű magyarországi dátumot jelenti, mely az Egységes Országos Térkép Rendszer alapja.
Az utolsó sor 2053 sorszámú GeogLinearUnitSizeGeoKey elnevezésű kulcs, tipusa kettőspontosságú valós szám, méterben kifejezett felhasználói geocentrikus hosszegység kifejezését teszi lehetővé. Mivel a kulcs értéke nem kód, hanem kettőspontosságú szorzó, ezért a tényleges értéket a címke tartalmazza mégpedig közvetlenül a típusjelzés után mivel a kulcs negyedik értéke 0.
A felvázolt példában az egyszerűség kedvéért a címke (tag) jegyzék elemeket nem részleteztük, hanem csak nevükkel és zárójelbe tett sorszámukkal jelöltük. Természetesen a valóságban ezek is az 5.2 ábrán szereplő módon kerülnek ábrázolásra.
|
|
5.3 ábra - a GeoTIFF raszter téri koordináta rendszerei |
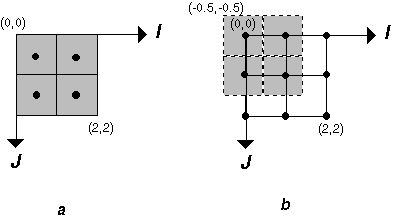
A 'közönséges' TIFF képek két koordináta térrel dolgoznak: a raszter térrel és az eszköz térrel. A raszter tér nem más mint értékek kétdimenziós tömbje. Attól függően, hogy a tömb elemei a valóságban mit ábrázolnak ezeket tekinthetjük területi képelemeknek, melyek egy négyzetnyi területre vonatkozó információt aggregálnak (5.3 ábra a részlet) vagy pontszerű képelemeknek, melyek például a pontok magasságát reprezentálják (5.3 ábra b részlet). Ha valamely gyakorlati okból a pontszerű képelemeket elemi négyzetekkel kell megjeleníteni (pld. a képernyőn vagy rajzgépen) úgy a keletkező pixel határok az ábra szerint eltolódnak, pld. a (0,0) koordinátájú pontot ábrázoló pixel bal felső sarokpontja (-0.5,-0.5) értéket vesz fel.
A TIFF a felbontási mértékegység (ResolutionUnit) címke sorszáma 296, X irányú felbontás (XResolution) címke sorszáma 282, Y irányú felbontás (YResolution) címke sorszáma 283, tájékozás (Orientation) címke sorszáma 274, X helyzet (Xposition) címke sorszáma 286 és Y helyzet (Yposition) címke sorszáma 287 segítségével kapcsolatot teremt a raszter tér és az eszköz tér között, azaz egyszerűbben szólva előírja, hogy a raszter hogyan jelenjen meg a képernyőn.
A GeoTIFF viszont az előbbi kapcsolattól függetlenül, azzal párhuzamosan kapcsolatot teremt a raszter tér és modell tér között illetve meghatározza a modell teret. A kapcsolatteremtést georeferenciának nevezi míg a meghatározást geokódolásnak. Más szóval meghatározza, hogy a raszter tér elemeinek mik a földi koordinátái és leírja a figyelembe vett koordináta rendszert.
A GeoTIFF modell terét ellipszoidi, geocentrikus, vetületi sík és magassági koordináta rendszerekkel jellemezhetjük. Ezekről a fogalmakról és a rendszereket meghatározó paraméterekről viszonylag részletesen szóltunk a 17. lapon ezért ezekre most nem térünk ki. Megjegyezzük azonban, hogy az esetek többségében vetületi sík koordináta rendszert használunk. A modell tér koordináta rendszerének jellemzésére geokulcsokat alkalmaz a rendszer. Ha a koordináta rendszer a GeoTIFF specifikáció szempontjából szabványos úgy jellemzésére egy-két geokulcs elég, ha a rendszer nem szabványos, hanem u.n. felhasználó által meghatározott, úgy több geokulcs kell a leírásához (ezek közül néhányat láttunk a szerkezeti példánk kapcsán). A specifikáció szerkesztői folyamatosan növelik a szabványos vetületi rendszerek számát. A modell koordináta rendszer megadása (geokódolás) mellett egy geokulccsal jellemezni kell a raszter tér milyenségét is, azaz, hogy területi vagy pont jellegű (5.3 ábra).
A következő és egyben utolsó feladat, hogy a GeoTIFF kódolja a koordináta transzformáció paramétereit, azaz azokat az adatokat, melyek segítségével kiszámolható az egyes pixelek koordinátája az előbbiekben rögzített modell koordináta rendszerben.
A 10.lap 1.pontjának képletei bemutatják kétdimenziós esetre az affin transzformációt. Amint a képletekből látható a transzformációnak 6 ismeretlen paramétere van, mely meghatározásához három olyan pontra van szükségünk, melyek koordinátái mindkét rendszerben ismertek. Ezeket a pontokat kapcsoló pontoknak nevezhetjük. A GeoTIFF lehetővé teszi, hogy privát címkében adjuk meg a kapcsoló pontokat az alábbiak szerint:
Név: ModelTiepointTag
címke azonosító = 33922(8482.H)
típus = DOUBLE (IEEE kettős pontosságú lebegőpontos)
N = 6*K, K= a kapcsolópontok száma
tulajdonos: Intergraph
A címke a kapcsolópont párok koordinátáit az
alábbi sorrendben tárolja:
ModelTiepointTag=(...,I,J,K,X,Y,Z,...), ahol I,J a pixel index, K a
hozzátartozó magasság érték digitális magasságmodell esetén, X,Y,Z pedig a
megfelelő modelltérbeli koordináták. Kétdimenziós esetben K és Z értéke zérus.
Ha a raszter tér és modell tér koordináta tengelyei
párhuzamosak, lehetőség van arra, hogy csak egy kapcsoló pontot adjunk meg a
ModelTiepointTag-ban és az X, Y (és Z) irányú méretarány változást megadó
alábbi privát címkével tegyük a transzformációt határozottá:
Név: ModelPixelScaleTag
címke azonosító = 33550 (830E.H)
tipus = DOUBLE (IEEE kettős pontosságú lebegőpontos)
N = 3
tulajdonos: SoftDesk
A címke 3 értéke a következő:
ModelPixelScaleTag=(ScaleX, ScaleY, ScaleZ). Erre is vonatkozik, hogy a
digitális magasságmodell kivételével ScaleZ=0 (a 10. lap 1. pontban a
méretarány tényezőket mx-el és my-al
jelöltük).
Általános transzformáció esetén a kapcsolópont címke helyett a
következő általános transzformációs címke használható
Név: ModelTransformationTag
címke azonosító = 34264(85D8.H)
tipus = DOUBLE (IEEE kettős pontosságú lebegőpontos)
N = 16
tulajdonos: JPL Cartographic Application Group
A transzformációs együtthatók a következő sorrendben helyezkednek el a
címkében:
ModelTransformationTag=(a,b,c,d,e,...,m,n,o,p).
A transzformáció a korábbi képlet háromdimenziós kibővítésével nyerhető homogén koordinátás mátrix szorzással történik. Az alábbi együttható értékek pillanatnyilag ugyan rögzítettek, de rögzített értékeikkel szerepelniük kell a címkében m=n=o=0 és p=1, e mellett kétdimenziós esetben c=g=k=i=j=l=0. Az (1) kifejezésben felírtuk erre az esetre a transzformációs mátrixot mégpedig mind a GEOTIFF mind pedig az általunk korábban alkalmazott jelölésekkel, hogy az olvasóban egyszerűbben tudatosodjon, hogy ezzel a transzformációval a korábbiakban már alaposan megismerkedett.
|
|
(1) |

Végül bemutatunk egy egyszerű példát a GeoTIFF specifikáció alapján.
A WGS84 dátumon alapuló UTM 60-as zónájába transzformált ortofotót kívánunk GEOTIFF formátumba alakítani. A kép bal felső sarkának derékszögű koordinátái: X= 350807.4m, Y= 5316081.3m. A szkennelt pixel méretarány 100 méter/pixel (az aktuális szkennelési dpi arány lényegtelen).
ModelTiepointTag = (0, 0, 0, 350807.4, 5316081.3, 0.0)
ModelPixelScaleTag = (100.0, 100.0, 0.0)
GeoKeyDirectoryTag:
GTModelTypeGeoKey = 1 (ModelTypeProjected
(VetületiModellTipus))
GTRasterTypeGeoKey = 1 (RasterPixelIsArea (RaszterElemTerületetJelent)
ProjectedCSTypeGeoKey = 32660 (PCS_WGS84_UTM_zone_60N)
PCSCitationGeoKey = "UTM Zone 60 N with WGS84"
Megjegyzések:
- Nem kellett külön meghatározni az ellipszoidi koordináta rendszert (GCS) mivel a PCS_WGS84_UTM_zone_60N tartalmazza mind a dátumot, mind a hosszegységet (WGS_84 és méter). Az idézet csak dokumentációs célokat szolgál.
- TIFF színten a "GeoKeyDirectoryTag" ahogy ezt már egy korábbi példában bemutattuk a következőképpen néz ki:
|
GeoKeyDirectoryTag(34735)=( |
|
||||||||||||||||||||||||
|
GeoAsciiParamsTag(34737)=( |
"UTM Zone 60 N with WGS84|") |
Bár a példában bemutatott földrajzi kulcsok a zárójeles angol magyar érték értelmezés segítségével jól érthetők a korrektség kedvéért külön is specifikáljuk az új kulcsokat:
Az 1025 sorszámú GTRasterTypeGeoKey azt mondja meg, hogy a pixelt területnek vagy pontnak kell tekinteni. Az első esetben az értéke 1 a második esetben 2.
A 3072 sorszámú ProjectesCSTypeGeoKey értéke egy SHORT típusú kód, mely azonosítja a 'szabványos' vetületi rendszert a dátummal együtt. A hazánkban alkalmazott vetületek közül a WGS84 dátumon alapuló UTM zónákon kívül csak a pulkovoi dátumú Gauss Krüger vetület zónái szerepelnek a kódok között.
A 3073 sorszámú PCSCitationGeoKey minden egyéb idézethez hasonlóan ASCII típusú (tehát a GeoAsciiParamsTag címkére hivatkozik és a kérdéses szöveg a címke értékei közt található) azt írja le szövegesen dokumentációs célból, hogy milyen dátumon alapuló milyen vetületről van szó.
Végül azok számára akik kevéssé ismerik a vetületeket el kell mondanunk, hogy mind az UTM-ben mind a Gauss-Krüger vetületben minden egyes zóna külön vetületi rendszernek számít.
Az ERDAS Imagine .img formátuma
Amint az 5.3 táblázatból látjuk a GeoTIFF 29 előfordulása után az ERDAS Imagine képfeldolgozó-GIS szoftver .img végződésű raszteres formátumának 23 előfordulása következik a vizsgált szoftverek által elfogadott raszteres formátumok listáján. Érdemes tehát röviden ezt a formátumot is bemutatni. Mielőtt azonban ezt megtennénk felhívjuk az érdeklődők figyelmét arra, hogy mivel ez a formátum is nyílt formátum, az ERDAS cég FTP szerveréről letölthetők azok a specifikációk, melyek C nyelven programozók számára lehetővé teszik e fájlok írására és olvasására szolgáló programok megírását. Ez a munka könnyíthető a 'C Programmers's Toolkit Packages' szoftver csomag gyűjtemény felhasználásával. A gyűjtemény kilenc ERDAS Imagine I/O program-csomagot tartalmaz, melyek függvényei beilleszthetők az .img fájl olvasására vagy írására készítendő C programba, erősen leegyszerűsítve ezzel a programozási munkát.
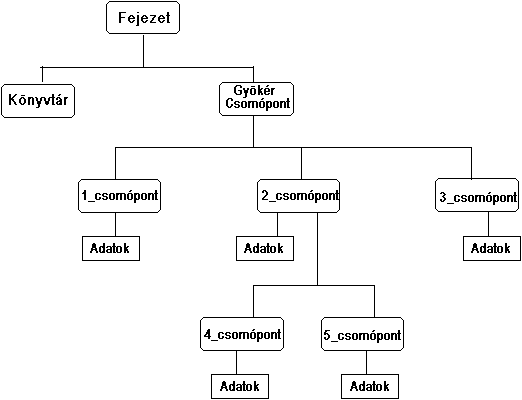
Ez a formátum is követi az ERDAS hierarchikus fájl formátum (HFA) struktúráját. Ez a felépítés objektum orientált elveken alapul. Minden objektum egy csomópontban helyezkedik el, neve és típusa van. Ezenkívül tartalmazhat al-csomópontokra mutató pointereket is. A fájl sémáját az 5.4 ábra mutatja be.
|
|
5.4 - ábra - az .img fájl felépítése |
A kép adatait tartalmazó objektumokat az 5.5 ábra szerinti fa szervezésben tartalmazza a fájl. Ezen az ábrán a tartalmi kérdésekre koncentrálunk ezért az objektumok formális neveitől eltekintettünk.
A felvázolt objektumok jó része opcionális azaz nem kötelező jellegű, ugyanakkor a formátum nyitott abból a szempontból, hogy a fejlesztőknek lehetőségük van új típusokkal bővíteni a struktúrát.
|
|
5.5 ábra - a kép objektumait tartalmazó fa |
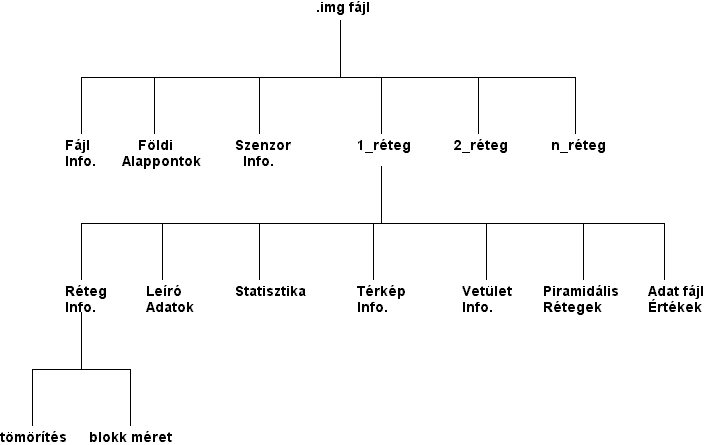
Az 5.5 ábra egyes blokkjai a következő információkat tartalmazzák:
A szenzor információ formátuma függ a szenzor típusától, melyet előre definiált szenzor fejezet objektumok határoznak meg. Ezek az új szenzorok megjelenése esetén bővíthető objektumok jelenleg a következők: ADRG_Header, ADRI_Header, DEM_Header, DTED_Header, TM_Header, MSS_Header, AVHRR_Header, SPOT_Header. Négy szenzorral a felsoroltak közül (TM, MSS, AVHRR, SPOT) viszonylag részletesen foglalkoztunk a 24.1 és 24.2 pontban.
Bármelyik szenzorról van is szó a blokk a következő általános információkat is tartalmazza: a letapogatás (szkennelés) időpontja, a szenzor kalibrációs adatai, a szenzor tájolása, az adatok eredeti dimenziója, az adattárolás formátuma, a csatornák száma, stb.
A raszter réteg információ egyebek közt tartalmazza a sorok és oszlopok számát, a réteg tipusát (folyamatos vagy tematikus), az adatok típusát (8 bites előjeles egész, lebegőpontos, stb.), a tömörítést (lehetőség van a sorkifejtő kódolás (run-length encoding) alkalmazására) és a blokkok méretét (alapértelmezésben a rendszer 64 K pixel-szer 64 K pixeles blokkokból építi fel a képet).
A leíró adatok a raszter réteg típusától függnek. Folyamatos réteg esetén ezek a hisztogram és a kontraszt táblázat. Ha tematikus rétegről van szó akkor a leíró adatok a hisztogramon kívül még tartalmazzák az osztályok nevét, az osztályok értékét és a vörös, zöld, kék értékeket magadó színtáblát. Ezen kívül megadhatók az osztályok területe és különböző más leíró adatai is.
A formátum igényli, hogy minden raszter réteg számára ki legyenek számolva a következő statisztikai mutatók: az adatfájl értékek maximuma és minimuma, az adatfájl értékek átlaga, az adatfájl értékek középső eleme (mediánja), és az értékek szórása.
Térképi Információt csak a georeferenciával ellátott fájlok tartalmaznak. Ezek az információk: a bal felső X, Y koordináta, a pixel méret, a térkép mértékegysége.
Georeferenciával rendelkező rétegek számára a következő vetületi információ generálódik: térképvetület, alapfelület (szferoid).
A piramidális rétegek létrehozása az ERDAS Imagine szoftver azon képessége, hogy ugyanarról a területről ismételt mintavételezéssel redukált kisebb felbontású rétegeket képes létrehozni a célból hogy a kisebb ablakokhoz gyorsan tudja illeszteni az előre kiszámított állományt.
Az .img fájl úgynevezett MIF (Machine Independent Format) formátumba vannak kódolva. Ez a kódolás azt eredményezi, hogy a fájl az adathordozóról a gép memóriájába különböző számítógép architektúrák esetén is fordítás nélkül vihető át.
Maga a kódolás tulajdonképpen különböző típus meghatározásokból áll, mely típusokhoz szabályok illetve megfelelő C nyelvű struktúrák vannak hozzárendelve. Ezek a szabályok megmondják, hogy az adott tipushoz (adat elemhez) milyen bitkép tartozik az .img fájlban és milyen a memóriában. Például, az előjel nélküli bináris értékhez (fekete-fehér kép pixelei), melyet EMIF_TU1-nek nevez az MIF, egy bájt tartozik a gép memóriájában, mig az .img fájlban egy bájt 8 darab EMIF_TU1 értéket tartalmaz.
Minden .img fájl végén egy ASCII sztring, a MIF adat könyvtár (MIF Data Dictionary), összefoglalja, hogy a HFA fájl csomópontjaiban (5.4 ábra), milyen objektumok vannak, az objektumnak milyen részei vannak, s azokat hány és milyen MIF típus írja le. A könyvtár pontos helyét a fájl fejezetében található pointer mutatja.
A HFA fájlok előre definiált objektum típusokkal dolgoznak, bár mint már említettük lehetséges az objektum típusok bővítése is.
Az előredefiniált objektum típusokat három fő csoportra oszthatjuk:
- Alap HFA fájl objektum típusok (Basic HFA File Object Types),
- .img objektum típusok (.img Object Types),
- külső fájl formátum fejezet objektum típusok (External File Format Header Object Types).
Hely hiányában csak az 1. csoport típusait soroljuk fel és bemutatunk egy .img rétegben található néhány típust.
A HFA fájl alapobjektumai a következők:
- Ehfa_HeaderTag
Az első 20 bájtot foglalja el ez a fejezet címke, ebből 16 bájton az EHFA_HEADER_TAG szöveg szerepel, míg a maradék 4 bájton egy mutató az Ehfa_File header rekordjára.
- Ehfa_File
Ez az objektum mutatókat tartalmaz a fájlon belüli szabad helyek listájára, a már említett MIF könyvtárra, illetve a gyökér csomópontra. Emellett megadja minden csomópont fejezeti részének (név, tipus, szülő/gyerek információ) a hosszát.
- Ehfa_Entry
Míg az előző objektum a csomópontok fejezeti részének hosszát adta meg, addig ez az objektum minden fejezet esetében megadja a mutatókat az azonos szinten lévő megelőző és követő csomópontra, a szülő és gyerek csomópontra, a csomóponthoz rendelt adatokra. Tartalmazza a csomóponthoz tartozó adatok bájtban kifejezett hosszát, a csomópont nevét, a csomóponthoz tartozó adatok tipusát és a módosítás idejét.
Mielőtt megismerkednénk néhány .img objektum típussal vázoljuk fel egy raszteres réteg HFA fájl fa részletét (5.6 ábra).
|
|
5.6 ábra - raszteres réteg HFA fájának részlete |
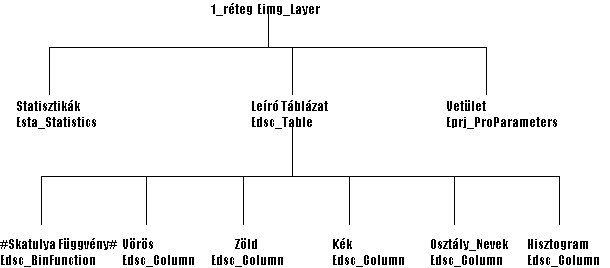
- Eimg_Layer
Az Eimg_Layer az alapcsomópontja az egy réteges képeknek. Ez írja le a kép szélességét (width) és magasságát (height), a réteg tipusát (layerType) mely tematikus vagy nem-tematikus lehet, a pixelek típusát (pixelType) mely 12 féle MIF tipusból választható, valamint a felhasznált blokkok szélességét (blockWidth) és magasságát (blockHeight). A többi adatot az ehhez a csomóponthoz kapcsolt 'gyerek' objektumok tartalmazzák.
- Esta_Statistics
Ez az objektum leírja a réteg statisztikai jellemzőit, a legkisebb pixel értéket (minimum), a legnagyobb pixel értéket (maximum), a középértéket (mean), a mediánt (median), az összes pixel módusát vagy leggyakoribb előfordulási értékét (mode) és szórását (stddev).
- Edsc_Table
Az objektum típus az információt tartalmazó oszlopok alapcsomópontja. Tulajdonképpen csak a belőle kiágazó oszlopok sorainak számát (numRows) tartalmazza.
- Edsc_BinFunction
Az 5.6 ábrán "SkatulyaFüggvénynek" neveztük ezt a funkciót, mely feladata, hogy a pixel értékeket oszlop indexekké képezze le valamilyen szabály szerint. Tulajdonképpen arról van szó, hogy a megadott skatulya számnak (numBins) megfelelően "beskatulyázza" a pixel értékeket a függvény adta index értékre. Evvel a fogalommal már találkoztunk a 22.2 pontban a hisztogram fogalmának ismertetésénél csak ott nem adtunk külön nevet a leképező függvénynek. Az objektum a már említett skatulya számon kívül tartalmazza a függvény típusát (binFunction Type), ami direkt, lineáris, exponenciális és explicit értékeket vehet fel, a függvény legalacsonyabb értékét (minLimit), legmagasabb értékét (maxLimit) valamint a skatulyák meghatározására szolgáló határokat (binLimits).
- Edsc_Column
Az oszlopban elhelyezett adatok objektum típusa. Tartalmazza a sorok számát (numRows), az oszlop adatainak kezdő címére mutató pointert (columnDataPtr), az oszlop adatainak típusát (dataType), valamint String tipusú adatok esetén a sztring maximális hosszát.
Az IDRISI oktatási GIS szoftver fájl formátuma.
Az IDRISI a raszter fájlokat képeknek angolul images hívja és .img kiterjesztéssel látja el. Minden kép meghatározott számú sorból és oszlopból áll, melyek kis négyzeteket - cellákat - alkotnak. Ezeket a cellákat mint különböző típusú számok (byte, egész vagy valós) egymásutánját tárolja. A számok fejezik ki a tulajdonságok értékeit, például a növényzeti osztályok kódját, visszaverődési értékeket, politikai - adminisztratív körzetek kódját, a digitális magasságmodell z értékeit, stb.
Lássunk egy nagyon egyszerű képet:
|
|
0 |
1 |
2 |
3 |
4 |
|
0 |
22 |
22 |
18 |
18 |
18 |
|
1 |
15 |
15 |
18 |
16 |
16 |
|
2 |
11 |
15 |
15 |
18 |
16 |
|
3 |
11 |
15 |
12 |
12 |
12 |
5.7 táblázat - egyszerű raszteres kép
A kép 5 oszlopot és 4 sort tartalmaz. Az értékek valamilyen földhasználati kategória kódjait jelenthetik. Az IDRISI a bal felső sarokban (0. sor, 0. oszlop) kezdi olvasni a képet majd oszlopról oszlopra illetve sorról sorra halad. A legegyszerűbb ASCII formátumban minden sorban egy cella értékét tárolja:
|
22 |
|
22 |
|
18 |
|
18 |
|
18 |
|
15 |
|
15 |
|
(...) |
|
11 |
|
15 |
|
12 |
|
12 |
A képeket rendszerint binárisan (angolul binary) kódolva tárolják, sorfolytonosan. Az adattípustól függően egy érték több vagy kevesebb helyet foglal el a memóriában. Az IDRISI támogatja a sorkifejtő tömörítést (angolul RLC = run length compression) és ezt a formátumot packed binary (magyarul tömörített bináris) formátumnak nevezi (mivel a cellaértéket követi a megszakítás nélküli előfordulásainak a száma):
- tömörítetlen: 22 22 18 18 18 15 15 18 16 16 11 15 15 18 16 11 15 12 12 12
- tömörített: 22 2 18 3 15 2 18 1 16 2 11 1 15 2 18 1 16 1 11 1 15 1 12 3
Sajnos a vizsgált képünk nem igazán alkalmas a tömörítésre. A tömörített képnek 4-el több bájtra van szüksége mint a tömörítetlennek. Olyan képeken azonban, ahol ugyanaz az érték nagy területet jellemez, a tömörítés elérheti sőt meg is haladhatja az 1:100 arányt.
Az 5.8 táblázat bemutatja az IDRISI adattípusait (a tömörítés kivételével alkalmazható a vektorfájlokra is):
|
|
memoria igény |
tartomány |
tömörítés |
|
byte |
1 bájt |
0-tól 255-ig |
igen |
|
egész |
2 bájt |
-32768-tól +32767-ig |
igen |
|
valós |
IEEE 4 bájt |
ą1*10 38, 7 értékes szám élesség |
nem |
5.8 ábra - az IDRISI adattipusai
Evidens, hogy a kép "nem tud" a saját méreteiről vagy arról, hogy milyen terület felel meg a valóságban egy cellának. Ezért szükségünk van egy "fejezet fájlra" a dokumentációs fájlra, mely leírja a kép jellemzőit. Ezen kívül még olyan attribútum fájlra is szükség volna, melyet a korszerűbb raszteres rendszerek képesek a tematikus rétegek osztályaihoz csatolni.
Mivel az IDRISI-ben a raszter fájl nem tartalmaz információt saját magáról, ezért ezt metaadatok formájában külön kell tárolnunk. Ezt a feladatot az úgy nevezett raszter dokumentáció fájlok (*.DOC) látják el. Minden képet el kell látni a hozzá tartozó .DOC-fájlal. Egy ASCII fájlról van szó, mely sorai metaadatokat tartalmaznak. Az 5.9 táblázatban összefoglaltuk a fájl kötelező és fakultatív tartalmát.
|
|
kötelező |
fakultatív |
megjegyzések |
|
Cím (Title) |
|
X |
leíró jellegű, érdemes használni |
|
Oszlopok / Sorok (Columns / Rows) |
X |
|
a raszter struktúráját adja meg |
|
Adat tipus (Data type) |
X |
|
az értékek típusa |
|
Fájl tipus (File type) |
X |
|
a fájl tárolási módja |
|
Minimum / Maximum érték (Minimum / Maximum value) |
X |
|
a határok automatikus vizsgálatára is van lehetőség |
|
Helyzeti hiba (Pos'n error) |
|
X |
x,y-helyzeti koordináta középhiba |
|
Felbontás (Resolution) |
|
X |
mindenegyes cella felbontása; a MaxX - MinX / oszlopok képlet szerinti automatikus számítás nem mindig jelenti a valódi térbeli felbontást |
|
érték hiba (Value error) |
|
X |
attribútum érték hiba, arányos vagy négyzetes közép, annak megfelelően hogy mit használt a PCLASS modul |
|
érték egységek (Value units) |
|
X |
m, osztályok, kg*ha-1*a-1 vagy bármely más egység |
|
Referencia rendszer (Reference system) |
X |
|
alapfelületi, vetületi információ |
|
Referencia egységek (Reference units) |
X |
|
m, ft, km, mi, deg, rad |
|
Minimum / Maximum X/Y koordináták (Minimum / Maximum X/Y coordinates) |
X |
|
a kép kiterjedése |
|
Távolság egység (Unit distance) |
X |
|
méretarány tényező, rendszerint 1.0; például, ha az értéke 2.0 és a referencia egység méterben van megadva, akkor 1 egység távolság 2 métert jelent a valóságban |
|
Jelző érték (Flag value) |
|
X |
olyan érték a raszterben, melynek különleges jelentősége van (háttér érték, adathiány, ...); a SURFACE modul használja a számításokhoz |
|
Jelző definíció (Flag definition) |
|
X |
a fenti érték jelentésének leírása |
|
Jelmagyarázat kategóriák (Legend categories) |
|
X |
szöveg a jelmagyarázathoz |
|
Teljesség, Konzisztencia, Megjegyzések és Eredet (Completness, Consitency, Comments and Lineage) |
|
X |
leíró rész, ha van információnk ki kell tölteni |
5.9 táblázat - a raszter dokumentációs fájl tartalom
A leíró adatok kezelésére az IDRISI az úgynevezett .val
fájlokat használja. Ezek két oszlopból álló ASCII fájlok, ahol az első oszlop
értékeinek tipusa egész (integer) a második oszlopé pedig egész (integer),
valós (real) vagy szöveg (string). Az első oszlop az objektumok, osztályok,
stb. kódját jelenti, míg a második oszlop a tulajdonképpeni jelentést vagy
értéket. Az IDRISI Windows-os verziói már képesek olyan többoszlopos leíró
adatfájlokat is kezelni, melyek ACCESS, dBASE vagy FoxPro adatbázis formátumban
vannak. Az alap fájl formátum azonban ezekben a rendszerekben is a kétoszlopos
.val fájl maradt.
· a következő részben megkezdjük a térbeli adatátviteli szabványok ismertetését
· esetleg visszatérhet az előző részhez
· illetve a tartalomjegyzékhez
Megjegyzéseit E-mail-en várja a szerző: Dr Sárközy Ferenc