Elemi adatstruktúrák
Az adatmodellezés folyamatában a témában érdekelt adatok, regisztereik és
azok kapcsolatait kell felderíteni. Ha általánosítani akarjuk a kérdést, és azt
akarjuk megvizsgálni, hogy az adatok kapcsolatainak melyek a lehetséges
alapformái, úgy az 1.4 ábra kapcsán a következő három alapkapcsolatot
emelhetjük ki.
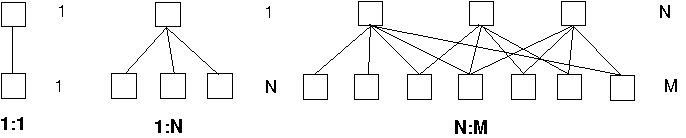
1.4 ábra - elemi kapcsolat típusok
Legegyszerűbb az 1:1 kapcsolat. Példaként megemlíthetjük a személy és
személyi-szám kapcsolatot, minden személynek egy személyi-száma van.
Hasonlóképpen utalhatunk a földrészlet és a településen belüli helyrajziszám
kapcsolatára.
Bonyolultabb kapcsolat az 1:N kapcsolat. Példaként szolgálhat a személy és
a tulajdonában lévő földrészlet vagy földrészletek, más példa lehet a személy
és gyermekei, stb.
Legbonyolultabb az N:M kapcsolat. Ha egy példán keresztül akarjuk
érzékeltetni ezt a kapcsolatot. Képzeljük el, hogy egy intézet, melynek három
tanszék van három feladatot végez. Ha a feladatokat úgy osztanánk szét a
tanszékek között, hogy egy feladatot csak egy tanszék dolgozói végezhetnek, úgy
az adatkapcsolat az 1:N sémával volna leírható. Ha azonban a különböző
tanszékek dolgozói bedolgoznak egymás témáiba, úgy a tanszéki dolgozó, illetve
a feladat kapcsolata csak az N:M formában írható le.
A különböző adatkezelő rendszerek, beleértve a korszerű adatbázis kezelő
rendszereket is, ezeknek a kapcsolatoknak valamelyik bonyolultsági fokát
kívánják megoldani. A hagyományos adatkezelés csak az 1:1 kapcsolat megoldására
volt alkalmas. A korszerű rendszerek igyekeznek az N:M problémát is megoldani,
habár ez nem minden esetben sikerül közvetlenül.
Az adatmodellezés során grafikusan felvázolt adatokat és kapcsolataikat a
számítógép számára a következő formában építhetjük fel. A legkisebb egység a bit,
amely egy kettes számrendszerben kifejezett számjegyet jelent. A második egység
a byte, amely rendszerint 8 bitből és egy ellenőrző bitből áll. A
következő egység a mező, mely egy önálló adatot jellemez. Több mező
alkot egy szegmenst, mely lehet egyszeri vagy ismétlődő. A
szegmens lényegében bizonyos összetartozó mezők legmagasabb logikai szintű
együttese. Több mező vagy szegmens alkot egy rekordot, melyet másképp
adatmondatnak is neveznek. Végül az adatok legmagasabb szervezeti formája a file,
másképp dossziénak is hívják.
Megjegyezzük, hogy a fenti adatszervezési egységek tulajdonképpeni adatokat
rögzítő részei, tehát a mező, szegmens, rekord és file mind a logikai, mind a
fizikai struktúrában jelen vannak. Egyes adatleíró vagy adatfeldolgozó nyelvek
ismernek magasabb szervezeti egységet is, ezek azonban általában a fizikai
struktúrához kötődnek és ezért az általános elemzésben nem kívánunk róluk
szólni.
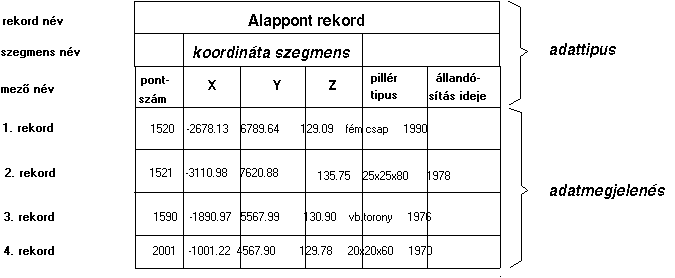
1.1 táblázat - az adatszervezési
egységek szemléltetése a geodéziai alappontok file-ján
A példa kapcsán feltűnik, hogy minden adatszervezési egység két jellemzővel
rendelkezik. Az egyik jellemző tulajdonképpen a fejléc, az adatok jelölését
tartalmazza, más kifejezéssel az adattípust adja meg, magának
a táblázatnak a rubrikái pedig az adatokat, azaz a mezők tartalmát, amik tulajdonságok
és értékek. Más szóval a mezőtartalmakat adatmegjelenésnek is
nevezzük.
Az adatmodellezéssel kapcsolatban említett adatstruktúrák a rekordokon
belül, de a rekordok között is megjelennek.
Nézzük meg mindenekelőtt a rekordok belső szerkezetét, majd a rekord
típusok egymáshoz történő kapcsolódási lehetőségeit.
Mind a fizikai, mind a logikai rekordok lehetnek lineárisak,
ami azt jelenti, hogy a rekordokhoz tartozó mezők vagy szegmensek egymástól
függetlenek és csak a rekord rendezési fogalmának vannak alávetve, alá- vagy
mellérendelés a rekordon belül nincs. A másik főstruktúra a nem
lineáris rekordok struktúrája, mely lehet fa-struktúra, háló-struktúra,
ciklikus-struktúra.
Készítsük el lineáris rekord formájában valamely alappont összes jellemző
adatát. Amint látjuk, a lineáris rekordban a rekord rendezési fogalma
a pontszám, a többi jellemző adat ehhez a rendezési fogalomhoz van
hozzárendelve.

1.5 ábra - egy geodéziai alappont
adatait tartalmazó rekord
Nézzünk példát a fa-struktúrára is. Készítsük el valamely ponton végzett észlelések
rekordját (1.6 ábra). Amint látjuk, a fa-struktúra esetén több hierarchia
szintet különböztetünk meg (A, B, C, D, E).
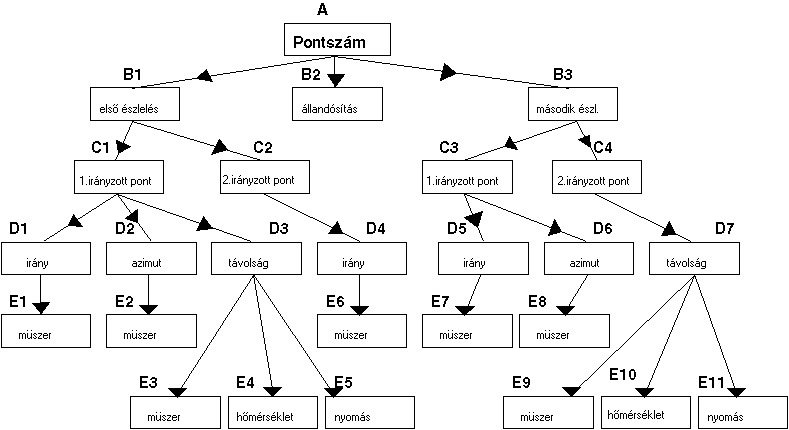
1.6 ábra - észlelési (szög és
távolság mérési) rekord fa struktúrában
Az előző példa modellezését háló-struktúrában is elvégezhetjük, ha
feltételezzük azt, hogy az egyes észleléseknél szereplő műszerek azonosak, azaz
E1=E2=E6=E7 és E3=E9 (1.7 ábra).
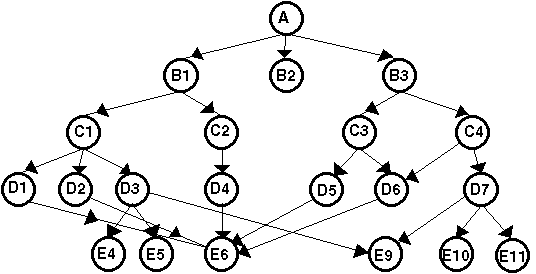
1.7 ábra - észlelési rekord háló
struktúrában
Az adatszervezési eljárásoknál
majd látni fogjuk, hogy a különböző struktúrájú adatmodelleknek más és más
logikai szintű tárolási és keresési eljárás fog megfelelni.
Végül a ciklikus struktúrára is mutatunk be példát, ha az alappont
észlelési rekordját csak az A, B1, C1, D1, E1 mezők figyelembevételével
alakítjuk ki.
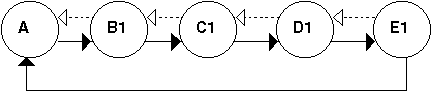
1.8 ábra - az észlelési rekord egy
része ciklikus struktúrában
Természetesen a fenti struktúrák a rekordok között is megjelenhetnek. Ez a
kapcsolatrendszer határozza meg az egész adatbázis, vagy az alséma jellegét. A
három legelterjedtebb adatbázismodell, melyeket a későbbiekben röviden
összefoglalunk, a hierarchikus, a hálós és a relációs.
Célszerű megjegyezni, hogy míg az első két modellben a fölvázolt alapstruktúrák
jól követhetők, addig a relációs modell esetén ez a kapcsolatrendszer a
felhasználó számára transzparensé válik.
A strukturált adatszerkezetek kódolása
Mielőtt rátérnénk az adatszervezési eljárások ismertetésére, vizsgáljuk meg
röviden a strukturált adatok leírási lehetőségeit. Az eddigiekben lényegében a
mezőtípusok, illetve rekordtípusok közötti kapcsolatokról beszéltünk azonban
már említettük, hogy minden adatszervezési egység esetében a típuson kívül
tartalmi megjelenésről is beszélünk. A tartalmi megjelenés, azaz a
tulajdonképpeni adatok leírása még ha nem számszerű adatokról is van szó, mint
például az állandósítási módok stb. gyakran számjegyekkel, azaz numerikus
kódokkal történik. Ez egyrészt azzal magyarázható, hogy íly módon elkerülhetők
a nyelvben levő kétértelműségek, másrészt, mivel így a tárolás rövidebb lehet.
A kódok a következő funkciókat látják el:
·
azonosítás,
·
osztályozás,
·
Információ.
Az eddigi tapasztalatok azt bizonyítják, hogy ezt a hármas funkciót
legcélszerűbben az úgynevezett párhuzamos kódolással lehet elérni. A
párhuzamos kódolás lényege az, hogy minden objektum kap egy azonosító kódot,
ami gyakorlatilag egy sorszám és ez az adott objektum vonatkozásában
változatlan marad. Ezen kívül azonban ellátjuk az illető objektumot osztályozó
kóddal is, amely osztályozó kód az objektum kapcsolatainak változásával
megváltozhat. Hasonlóképpen szükség esetén az objektum kódját informatív
kóddal is kiegészíthetjük, pl. a városnévvel, dátummal stb. Az ilyen módon
kialakított párhuzamos kódok egyértelműsége biztosított, nincs belső
hierarchiájuk és így tetszés szerinti kapcsolatok alakíthatók ki a különböző
kódolt objektumok, illetve azok jellemzői között.
Bár a kódolás nem tartozik az adatbázis koncepció lényegéhez, mégis
célszerű felhívni a figyelmet a helyes kódolás fontosságára. Érdekes módon az
adatbázis koncepció magyarországi elterjedésének kezdetén a kódolásnak túlzott,
indokolatlan jelentőséget tulajdonítottak, míg az utóbbi időben úgy tűnik, hogy
a jelentőségét teljesen elhanyagolják. Kétségtelen, hogy a kódolás alapfeladata
az azonosítás. A jó kódnak azonban emellett még a lehetőségekhez képest
maximális információtartalma is kell hogy legyen. Különösen igaz ez akkor, ha
az azonosításhoz amúgy is szükséges helyértékek növelése nélkül valósítható meg
az információ gazdagság. Jó példaként említsük meg a geokódokat melyek úgy
képesek azonosítani a területi objektumokat, hogy egyúttal azok térbeli
elhelyezkedésére is információval szolgálnak. Rossz példaként a
gépjárműrendszámok új rendszerét említhetjük (a régi rendszámok rendszere sem
volt túl jó), mely ahelyett, hogy a külföldi országok rendszámkódolásához
hasonlóan információt szolgáltatna a gépkocsik területi hovatartozásáról, az
azonosításon kívül gyakorlatilag semmilyen információt sem nyújt.
·
a következő rész az elemi
adatszervezés kérdéseit tárgyalja,
·
visszatérhet az előző részhez is,
·
vagy a tartalomjegyzékhez.
Megjegyzéseit E-mail-en várja a
szerző: Dr Sárközy Ferenc
Created
using: Lightning HTML Editor
Version 2.03.1997