Adatbáziskezelő rendszerek
Az ember és az adatbázis kapcsolata
Az adatbázissal az emberek négy különböző csomópontban találkoznak. A négy csomópont különböző szakmai, számítástechnikai felkészültségű munkatársat igényel. Az első csomópontban az adatbázis létrehozásakor annak adatokkal történő feltöltése előtt számítógépes szakemberek általában alkalmazói és rendszerprogramozók kommunikálnak. Ez a csomópont az adatbázis sémája, melyet az adatdefiniáló nyelv segítségével alkotnak meg.
1970-ben a már létrejött tapasztalatok alapján egy amerikai kutatócsoport "DATA BASE TASK GROUP (DBTG)" kidolgozott egy koncepciót a korszerű adatkezeléshez szükséges és többé-kevésbé szabványosított nyelvek vonatkozásában. A koncepció értelmében két nyelv létrehozása szükséges. Az egyik a DDL (Data Definition language = adatdefiníciós nyelv) mint önálló nyelv az adatstruktúrák létrehozására és definiálására szolgál. Lényegében azt a feladatot látja el, amit az általunk ismert algoritmikus nyelvek deklarációs része.
Egy másik nyelv a koncepció szerint arra szükséges, hogy a programozási nyelvbe beépülve növelje annak hatékonyságát és lehetőségeit a DDL nyelv által definiált adatrendszerek feldolgozásában. Ezt a nyelvet a koncepció szerint DML (Data Manipulation language) azaz adatmanipulációs nyelvnek nevezték.
A két nyelv létrehozása lehetővé tenné, hogy az adatokat több felhasználó több formában azonos időben felhasználja, hogy különféle visszakeresési módszerek legyenek alkalmazhatók ugyanabban a struktúrában, hogy az adatok fizikai tárolása az operációs rendszer gondja legyen és ne terhelje a felhasználói programozót, hogy bonyolult és integrált adatstruktúrák legyenek szervezhetők. A koncepciót eredeti formájában a hálós adatbázis modellre dolgozták ki. Mivel a hierarchikus modell kialakulása időben megelőzte a hálós modellét, a koncepció ezek számára az adatbázisok számára is alkalmazható. A relációs adatmodell azonban később alakult ki és a két nyelv funkcióit egy nyelvben az SQL-ben realizálta.
Adatbázis típusok
A jelenleg működő korszerű adatbázisok négy alapvető adatmodellt realizálnak:
- - a hierarchikus adatmodellt,
- - a hálós adatmodellt,
- - a relációs adatmodellt és az
- - objektum orientált adatmodelt.
Mivel napjainkban a kereskedelmi szoftverek legnagyobb része a relációs adatmodellt valósítja meg, ezért erről egy kicsit részletesebben szólunk. A másik három modellt csak vázlatosan ismertetjük.
Hierarchikus adatmodell
A hierarchikus adatmodell fák olyan együttese, mely erdőt alkot. Az 1.6 ábrán már szemléltettünk egy fa-struktúrát, ott azonban csak egy fáról volt szó és ennek a fának a csomópontjai nem rekordok, hanem mezők voltak. A hierarchikus adatbázisok fákba rendezett rekordokból állnak.
E fa-struktúra lényege az, hogy a hierarchia szintek között a szülő és gyermekek vonatkozásában mindig az 1:N kapcsolat érvényesül. A hierarchikus struktúrában végrehajtható legelterjedtebb művelet a fa végigjárása. Ez azonban csak egy irányból, a gyökértől a levelek felé irányítottan végezhető. Másik probléma az, hogy a fa- struktúrában az N:M kapcsolatok közvetlenül nem realizálhatók. Hátránya a modellnek az is, hogy az azonos hierarchia szinten, de különböző fákon található rekordok között csak igen gazdaságtalanul lehet a kapcsolatokat realizálni. Bár úgynevezett virtuális rekordok kialakításával a fák kétirányú bejárása megoldható, valamint redundáns csomópontok beiktatásával az N:M kapcsolatok is lekezelhetők, a gyakorlatban ezt a modellt egyre kevéssé használják fel alfanumerikus adatbázisok létrehozására. Hogy mégis szóltunk róla, az azzal magyarázható, hogy a grafikus adatok leírásához nagyon gyakran alkalmazzuk ezt a modellt, mind a síkbeli, mind a térbeli alakzatok esetén.
Hálós adatmodell
A hálós adatmodell legkomplexebb leírását a CODASIL DBTG (CONFERENCE ON DATA SYSTEM LANGUAGES DATA BASE TASK GROUP) [2] 1976-os jelentése tartalmazza. A jelentés lényegében az előzőekben már felvázolt DDL és DML nyelvek olyan leírását tartalmazza, mely alkalmas a hálós adatmodell megvalósítására.
A javaslatban az adatstruktúra alapelemei hasonlóak a hagyományos adatszervezésnél megismertekhez. Mezőkből, illetve szegmensekből (a javaslat szerint adat aggregátokból) épül fel a logikai rekord. A javaslat is szigorúan megkülönbözteti az adattípust az adatmegjelenéstől. Egy adott adattípusnak tetszőleges számú megjelenése engedélyezett. A továbbiakban elmondandók a típusokra vonatkoznak.
A logikai rekordoknál magasabb adattípus szerkezet a halmaz (set) "gazda" rekord típusból és tetszőleges számú "tag" rekord típusból állhat. Ugyanaz a rekord típus lehet az egyik halmazban "gazda", míg a másikban "tag". Egy halmazon belül a "gazda" rekord típus és a "tag rekord típusok vonatkozásában az "1:N kapcsolat realizálódik. Fordítva a "tag" rekord típusok a "gazda" rekord típus felé az N:1 viszonyt valósítják meg. Következésképpen az N:M viszony megvalósításához két halmaztípusra és három rekord típusra van szükség.
Az 1.18 ábra példáján az orvos rekord típus, alkalmazott rekord típus és a gyermek rekord típus közötti kapcsolatokat két adat halmaz típus kialakításával fejezhetjük ki. Az első halmaz "gazda" rekord típusa az orvos, a "tag" rekord típusok pedig a gyermek és az alkalmazottak.
Látható, hogy a felbontás eredményeképpen realizálható az M:N viszony, hisz a gyermek "tag" rekord típusnak két "gazda" rekord típusa van.
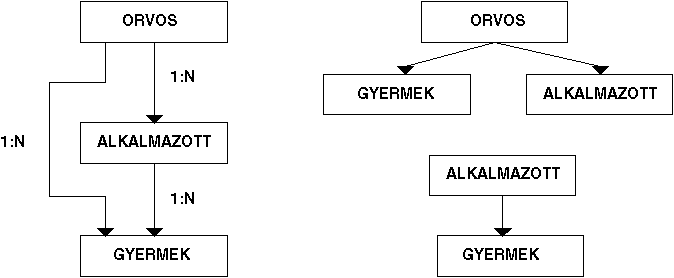
1.18 ábra - N:M viszony realizálása hálós adatmodellben
A javaslat alapján több kereskedelmi adatbáziskezelő rendszert is létrehoztak, ilyen például az IDMS, az IBM 360/370-es sorozatra, a DMS 1100, az UNIVAK 1100-ra vagy az IDS/II a HANIVEL 6000-es gépekre.
Relációs adatbázis modell
Ez az adatbázis modell napjainkban már szinte általános elterjedésnek örvend a leíró adatok kezelésében, de több GIS szoftver relációs adatbáziskezelőt használ a grafikus adatok tárolására is.
A modell kialakítását alapvetően az inspirálta, hogy az adatbázis megtervezésekor az adatokat a felhasználó számára áttekinthető és egyszerűen kezelhető táblázatokba lehessen elhelyezni, mely táblázatos forma erős hasonlatosságot mutat a hagyományos adatszervezés rekord strukúrájához.
Egyéb, később ismertetendő különbségek mellett azonban ennek a táblázatos modellnek az az alapvető különbsége a hagyományos adatmodelltől, hogy nem csak egy táblázat kezelésére alkalmas, hanem több, egymással összefüggő táblázat feldolgozásával éri el a kívánt eredményt. A feldolgozás alapját a halmazelméleti relációs kalkulus szolgáltatja. Éppen ezért célszerű, ha a modell megismerését a matematikai alapokkal kezdjük.
A relációs adatmodell
Matematikai alapja a halmazelméleti reláció, ami nem más, mint egy részhalmaza a "domain"-ek Descartes-szorzatának. Domain-nek nevezzük az értékek valamilyen halmazát. (Pl. az egész számok halmaza, vagy valamely karakterek sorozatának a halmaza, vagy a (0,1) halmaz, stb.).
A D1, D2,..., Dk domain-ek Descartes-szorzata alatt, amelyet a továbbiakban D1 x D2 x ... x Dk -val jelölünk, az olyan k-asok halmazát értjük, amelynek komponensei sorra a D1, D2 , ... Dk halmazokból valók, tehát:
|
D1 x D2 x ... x Dk=
((v1,v2,...,vk) | v |
Például: Legyen k = 2, D1 = {0,1), D2 = {a,b,c), akkor
D1 x D2 = ((0,a),(0,b),(0,c),(1,a),(1,b),(1,c)).
A reláció valamilyen részhalmaza az egy vagy több domain Descartes-szorzatának. A fenti példa esetében a ((0,a),(0,c),(1,b)) részhalmaz egy reláció, melyet a fenti D1, D2 halmazok között értelmeztünk. Egy reláció halmazában a tagokat tuple-nek nevezzük, amely k-fokú, jelölésben: (v1,v2,...,vk).
A relációt célszerű táblázatok formájában elképzelni, illetve ábrázolni, ahol minden sort egy tuple-nek és minden oszlopot egy komponensnek tekintünk. Az oszlopokat gyakran névvel látjuk el, ezeket attribútumoknak nevezzük. Az attribútumok halmazát a reláció sémájának hívjuk.
Ha egy relációt "REL"-nek nevezünk és a komponensek neveit (attribútumait) A1,A2,...,Ak -val jelöljük, akkor a reláció sémáját leírhatjuk mint
REL (A1,A2,...,Ak).
Pl. adott:
|
PONT_INFO |
|
|
|
|
P_SZÁM |
X |
Y |
Z |
|
101 |
1125,34 |
-615.90 |
200.145 |
|
102 |
1615.97 |
-456.67 |
217.987 |
|
103 |
1717.88 |
120.42 |
275.754 |
1.10 táblázat - geodéziai alappontok koordinátajegyzéke
Akkor PONT_INFO(P_SZAM,X,Y,Z) a reláció sémája, attribútumai rendre A1=P_SZÁM, 2=X,..., domain-jei pedig rendre D1=(101,102,103), D2=(1125.34,1615.97,1717.88),..., és egy tuple pedig t1=(101,1125.34,-615.90,200.145)
A reláció sémák egy gyűjteményét a relációs adatbázis sémájának nevezzük, a relációk aktuális értékeinek halmazát pedig a relációs adatbázis névvel illetjük.
A relációs adatbázison végezhető műveletek.
Minden művelet a relációs algebra alapműveleteivel modellezhető. Ezen alapműveletek:
- Unió: Ha a két halmaz R és S, akkor R
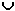 S jelöli azon tuplek halmazát, amelyek
akár R-ben, akár S-ben vannak.
S jelöli azon tuplek halmazát, amelyek
akár R-ben, akár S-ben vannak. - Különbség: Az R és az S halmaz különbsége (R - S) a tuplek azon halmaza, melyek tagjai az R-nek, de S-nek nem.
- Descartes-szorzat: Lásd korábban.
- Projekció: Ha R egy k változós reláció, akkor
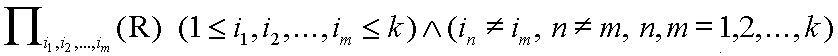
jelölje azt a halmazt, amelynek komponensei rendre az R i1-dik, i2- dik, stb. komponensei és m-ed rendű.
Például, ha R = (a,b,c,d,e), akkor
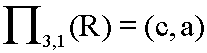 .
.
- Szelekció: Ha R = (t ,t ,...t ), akkor
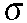 F(R) jelöli azon R-ben
lévő tuple-ok halmazát, amelyek kielégítik az F feltételt.
F(R) jelöli azon R-ben
lévő tuple-ok halmazát, amelyek kielégítik az F feltételt.
Ha R = ((H,I),(M,B),(H,A),(J,F)) és F = "1 = H", akkor
![]() 1=H(R)
= ((H,I),(H,A)).
1=H(R)
= ((H,I),(H,A)).
További leszármaztatott műveletek:
- Metszet: R
 S = R - (R - S).
S = R - (R - S). - Hányados:
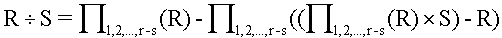 .
. - Összekapcsolás:
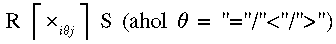 , például
, például
![]()
- Természetes
kapcsolás: R
 S csak olyan
relációknál használható, ahol az oszlopoknak neveik vannak.
S csak olyan
relációknál használható, ahol az oszlopoknak neveik vannak.
A felsorolt műveletek teszik lehetővé az adatbázis lekérdezését, módosítását, stb. A lekérdezések alapegységei lehetnek a tuple-ok ekkor tuple relációs kalkulusról beszélünk, illetve a domainek ez esetben a módszer neve domain relációs kalkulus.
A matematikai tárgyalás során nem alkalmaztunk korlátozásokat, a reláció kialakításában résztvevő domain-okra illetve a Descartes-szorzat révén létrejött tuple-ok halmazára. Az adatbázissal szemben támasztott gyakorlati követelmények azonban megkívánják, hogy az adatbázis céljaira fölhasznált relációk bizonyos tulajdonságokat kielégítsenek. Ezek a tulajdonságok a következők:
- A táblázat nem tartalmazhat két teljesen azonos sort, két sor legalább egy tulajdonság értékben el kell hogy térjen egymástól.
- A táblázat soraira egy tulajdonság konkrét értékével hivatkozunk. Ennek a tulajdonságnak egyedinek kell lennie az egyes sorok vonatkozásában. Ezt a tulajdonságot magában foglaló oszlopot elsődleges kulcsnak nevezzük. Előfordul, hogy nem találunk egy olyan oszlopot (tulajdonságot), mely valamennyi sor számára egyedi lenne. Ebben az esetben két vagy több oszlopból alakítjuk ki az úgynevezett összetett elsődleges kulcsot. Előfordulhat, ennek az esetnek a fordítottja is, amikor több olyan tulajdonság fajtát találunk, amely segítségével egyedileg lehet hivatkozni a táblázat soraira. Ezeket a tulajdonság fajtákat kulcs jelölteknek nevezzük, és belőlük választhatjuk ki az elsődleges kulcsot.
- A matematikai reláció fogalommal ellentétben mivel az oszlopok tulajdonságait alfanumerikusan jelöljük, azok sorrendje tetszőleges lehet. A fentiekből ugyanakkor az is következik, hogy egynél több azonos nevű oszlop egy relációban nem lehet.
- A sorok sorrendje a relációban tetszőleges. Már említettük a nagy hasonlóságot a hagyományos adatszervezés egységeivel. Ez a hasonlóság jogosít fel bennünket arra, hogy a tupleket a továbbiakban rekordoknak nevezzük, esetenként megadva a fokukat, azaz hogy hány mezőből állnak. A relációk tulajdonságaiból ugyanakkor levonhatunk bizonyos különbségeket is, a hagyományos adatszervezési és a relációs táblázatok között. Mindenekelőtt arra utalunk, hogy a relációs táblázatokban nincs helye a szegmenseknek, azaz a mező és rekord között elhelyezkedő adategységnek. Másodszor a rendezettség szükségszerűsége is megkülönbözteti a hagyományos adatszervezést a relációs táblázatoktól. Annak érdekében, hogy a relációs táblázatokban helyet foglaló adatok stabil adat struktúrát biztosítsanak, melyeken a műveleteket hatékonyan lehet végezni, s melyek módosítása is egyszerűen és konzisztensen hajtható végre, a különböző relációs adatbázis szoftverek más és más szigorúsággal úgynevezett normalizálási műveletek végrehajtását kívánják meg a betöltendő táblázatokkal szemben. A maximális normalizáltságot három fokozatban közelíthetjük meg.
· Első normál forma:
Első normál formában akkor van a reláció, ha minden mezőjében elemi, azaz nem összetett értékek szerepelnek. Az 1.11-es táblázatban szereplő reláció nem normalizált, mivel a megye és városok vonatkozásában megőrizte a hierarchikus struktúrát. Ha ezt a táblázatot a hierarchia feloldásával normalizáljuk, akkor az 1.12 táblázatban közölt relációt kapjuk, mely első normál formában van.
|
VÁROS |
||
|
MEGYE |
VÁROS |
LAKÓSSZÁM |
|
HEVES |
Gyöngyös |
40000 |
|
|
Eger |
62000 |
|
|
Hatvan |
25000 |
|
PEST |
Vác |
50000 |
|
|
Gödöllő |
30000 |
1.11 táblázat - a VÁROS táblázat a hierarchia megszüntetése előtt
|
VÁROS |
||
|
MEGYE |
VÁROS |
LAKÓSSZÁM |
|
HEVES |
Gyöngyös |
40000 |
|
HEVES |
Eger |
62000 |
|
HEVES |
Hatvan |
25000 |
|
PEST |
Vác |
50000 |
|
PEST |
Gödöllő |
30000 |
1.12 táblázat - a VÁROS táblázat a hierarchia megszüntetése után - első normál formában
· Második normál forma.
Második normál formában akkor van a reláció, ha egyrészt az első normál forma követelményeit kielégíti, másrészt minden olyan tulajdonsága, amely nem elsődleges kulcs, vagy annak része, teljes függéssel függ az elsődleges kulcstól.
A teljes függés fogalmával tulajdonképpen két fogalmat próbáltunk összefoglalni. Az egyik fogalom a funkcionális függés, amely egy adott relációban azt jelenti, hogy valamely tartomány akkor függ funkcionálisan egy másik tartománytól, ha bármely időpontban az első tartomány minden értékéhez a második tartomány egy meghatározott értéke tartozik. A második fogalom ahhoz kapcsolódik, hogy teljes függés esetén a kérdéses tartományok az összetett kulcs együttes értékéhez kötődnek és nem önállóan annak valamelyik tagjához. A bevezetett fogalmak illusztrálásához nézzük meg az 1.13 táblázatot.
|
INGATLAN |
|||
|
VÁROS
v. KÖZSÉG |
HELYRAJZI
SZÁM |
FORGALMI
ÉRTÉK |
TÁJEGYSÉG |
|
Kecskemét |
1612 |
1600000 |
Duna-Tisza köze |
|
Kecskemét |
1613 |
850000 |
Duna-Tisza köze |
|
Mátraszentimre |
0016 |
120000 |
Mátra |
|
Tokaj |
1060 |
1300000 |
Hegyalja |
1.13 táblázat - az INGATLAN táblázat nincs második normál formában
Az INGATLAN nevű reláció kulcsa összetett a város vagy községnév, és a helyrajzi szám, mivel ugyanaz a helyrajzi szám több városban is szerepelhet. A forgalmi érték teljes függéssel függ az összetett elsődleges kulcstól, hiszen a telek értéke csak egy konkrét községen belül értelmezhető. Más a helyzet a tájegységgel. A tájegység nem függ a helyrajzi számtól, az összetett kulcs egyik összetevőjétől, hanem funkcionális függéssel kizáróan a város vagy községnévtől, azaz az összetett kulcs első összetevőjétől függ. Következésképpen ez a reláció nincs második normál formában. Ahhoz, hogy a relációt második normál formába tegyük, az 1.14 és 1.15 táblázatok szerint két részre kell bontatunk. Az INGATLAN és TÁJEGYSÉG relációkra. Amint látjuk, itt már mind a két reláció második normál formában van. Azt is látjuk, hogy a relációk normalizálásával bizonyos redundancia fölszámolására is lehetőségünk volt.
|
INGATLAN |
||
|
VÁROS
v. KÖZSÉG |
HELYRAJZI
SZÁM |
FORGALMI
ÉRTÉK |
|
Kecskemét |
1612 |
1600000 |
|
Kecskemét |
1613 |
850000 |
|
Mátraszentimre |
0016 |
120000 |
|
Tokaj |
1060 |
1300000 |
1.14 táblázat - az INGATLAN táblázat miután leválasztottuk a TÁJEGYSÉG-et, második normál formában
|
TÁJEGYSÉG |
|
|
VÁROS
v. KÖZSÉG |
TÁJEGYSÉG |
|
Kecskemét |
Duna-Tisza köze |
|
Mátraszentimre |
Mátra |
|
Tokaj |
Hegyalja |
1.15 táblázat - az TÁJEGYSÉG táblázat miután leválasztottuk a INGATLAN-t, második normál formában
· Harmadik normál forma
A harmadik normál forma meghatározásának megértéséhez meg kell ismerkednünk az úgynevezett tranzitív függőség fogalmával.
Egyes relációkban lehetnek olyan kulcs jellegű tartományok, melyek az adott relációban nem elsődleges kulcsok de más reláció egyedeit egyértelműen azonosíthatják. Ezeket a tulajdonságokat reprezentáló értékeket idegen kulcsoknak nevezzük. Ha van egy olyan relációnk, melynek minden oszlopa függ az elsődleges kulcstól, de emellett valamely oszlopa függ egy másik oszloptól, egy idegen kulcstól is, akkor tranzitív függésről beszélünk.
Harmadik normál formában azok a második normál formájú relációk vannak, melyek nem tartalmaznak tranzitív függést.
Nézzük meg egy második normál formában lévő reláció harmadik normál formába alakítását az 1.16, 1.17 és 1.18 táblázatok példáján.
|
INGATLAN |
|||
|
KÖZSÉG |
HELYRAJZI
SZÁM |
FORGALMI
ÉRTÉK |
TULAJDONOS
SZEMÉLYI SZÁMA |
|
Adács |
1618 |
1050000 |
1 330506 0164 |
|
Abasár |
1618 |
820000 |
2 501112 1002 |
|
Heves |
2ö6ö |
450000 |
1 440323 0205 |
|
Heves |
1510 |
600000 |
2 710127 1011 |
1.16 táblázat - az INGATLAN táblázat második normál formában, melyet harmadik normál formára alakítunk
Amint látjuk, az 1.16 táblázat INGATLAN nevű relációjának minden elsődleges kulcson kívüli oszlopa teljes függéssel függ az összetett elsődleges kulcstól, a községnévtől és helyrajzi számtól, azaz a reláció második normál formában van. Ugyanakkor azt tapasztaljuk, hogy a tulajdonosok személyi száma alkalmas oszlop más reláció egyedeinek egyértelmű azonosítására, azaz relációnkban idegen kulcsot is találtunk. Ez az idegen kulcs egyértelműen azonosítja a tulajdonosok nevét, azaz a tulajdonosokat nemcsak az elsődleges kulcs, de az idegen kulcs is azonosítja, azaz a relációban tranzitív függés van, következésképpen nincs harmadik normál formában.
A tranzitív függőség kiküszöbölése érdekében válasszuk ketté a relációt egy INGATLAN és egy TULAJDONOS relációra. Ebben az esetben már mind a két reláció harmadik normál formájú lesz.
|
INGATLAN |
|||
|
KÖZSÉG |
HELYRAJZI
SZÁM |
FORGALMI
ÉRTÉK |
TULAJDONOS
SZEMÉLYI SZÁMA |
|
Adács |
1618 |
1050000 |
1 330506 0164 |
|
Abasár |
1618 |
820000 |
2 501112 1002 |
|
Heves |
2060 |
450000 |
1 440323 0205 |
|
Heves |
1510 |
600000 |
2 710127 1011 |
1.17 táblázat - az INGATLAN táblázat harmadik normál formában
|
TULAJDONOS |
|
|
TULAJDONOS
SZEMÉLYI SZÁMA |
TULAJDONOS
NEVE |
|
1 330506 0164 |
Kiss Róbert |
|
2 501112 1002 |
Nagy Eszter |
|
1 440323 0205 |
Tamás Károly |
|
2 710127 1011 |
Kúti Júlia |
1.18 táblázat - a TULAJDONOS táblázat harmadik normál formában
· Kapcsolat a relációs adatbázissal - az SQLnyelv
A relációs adatbázis kezelő rendszerek napjainkban már általánossá váltak, mind a személyi számítógépek, mind a munkaállomások, mind pedig a nagygépek programellátásában. Az adatok elérésére, a rendszer adatföltöltésére és karbantartására olyan lekérdező nyelvek alakultak ki, melyek mind logikájukban, mind pedig formális megjelenésükben egyre inkább hasonlítanak az Oracle adatbázis kezelő rendszer SQL (Structured Query Language) lekérdező nyelvéhez, úgyhogy azt mondhatjuk, hogy az SQL mintegy a szabványnyelv szerepét játssza a relációs adatbázisok hozzáférési folyamatában.
Az SQL jelentőségét nemcsak az adja meg, hogy a korszerű alfanumerikus adatbázisokat a segítségével tudjuk elérni, hanem az is, hogy a földrajzi információs rendszer szoftverek egyre inkább úgy készülnek, hogy egy interfész program segítségével közvetlen kapcsolatot tudnak kialakítani relációs adatbázisokkal. Például az ARC/INFO földrajzi információs rendszer az RDBI (Relational Data Base Interface) program segítségével közvetlen kapcsolatra tud lépni Oracle adatbázisokkal, melyeket az ARC/INFO-ból SQL-el kérdezhetünk le. Ily módon az SQL gyakorlatilag bevonult a térinformatika eszköztárába is.
Az SQL legfontosabb utasítása a SELECT utasítás.
Formája:
SELECT (oszlop(ok) neve) FROM (táblázat(ok)) WHERE (feltételek)
Amint a kifejezésből látjuk, egyszerre több oszlop nevét is kiválaszthatjuk. Ilyenkor az oszlop neveket vesszővel választjuk el. Hasonlóképpen lehetséges az oszlopokat több táblázatból is nyerni, erre példát a későbbiekben látunk.
A harmadik sorban a feltételeket adtuk meg. Ezek igen gazdag környezetből választhatók ki, példáinkban megpróbálunk egy-két jellegzetes feltételt bemutatni.
Első példánkban
SELECT FORGALMI_ÉRTÉK FROM INGATLAN WHERE KOZSÉG = 'HEVES' AND HRSZ < 2 000
az INGATLAN táblázat (1.17 táblázat) forgalmi érték oszlopából vagyunk kíváncsiak arra, vagy azokra a mezőkre, melyek Heves községhez tartoznak és a helyrajzi számuk kisebb mint 2 000. Kérdésünkre a válasz szintén egy táblázat
FORG ÉRTÉK 600 000
amely esetünkben egy oszlopból és egy sorból áll, tehát tulajdonképpen egy mezőérték. Formailag érdemes megjegyezni, hogy a logikai feltételek között szereplő karakter kifejezéseket mindig egyes idézőjelbe tesszük, az egyenlőség mindkét oldalán pedig egy- egy üres helyet szerepeltetünk.
Következő példánkban az 1.12-es táblázatban szereplő város relációt kérdezzük le, a városnév és lakós-szám oszlopok szerint. Olyan városokat és lakosságszámot keresünk, melyek Heves megyében vannak és a lakosság száma nagyobb egyenlő 40 000-nél. Az eredményt az alábbi táblázat szolgáltatja.
VÁROS NÉV LAKOS SZÁM GYÖNGYÖS 40 000 EGER 62 000
Amint már említettük, a logikai feltételek bőséges tárháza áll rendelkezésünkre. Ezek közül kiegészítésképpen még két műveletet szeretnénk megemlíteni. Ezek az IN és a LIKE.
IN (150, 600, 900 1000) IN (' ',' ') LIKE ' *'
Az IN, amint láthatjuk, két féle képen szerepelhet. Ha a WHERE utáni mezőnév tartalma számokat jelent, úgy azokat a mezőket választja ki, melyek vagy egyenlőek a felsorolásban szereplő számokkal, vagy a nyíllal kijelölt két szám között helyezkednek el. Amennyiben a kérdéses mező tartalma karakter, úgy azokat választja ki közülük, melyek azonosak az IN után zárójelben, egyes idézőjelben, egymástól vesszővel elválasztott karakter sztringekkel.
A LIKE logikai operátor csak karakteres mező értékekre használható. Valamennyi mezőt kiválasztja, melyek első néhány karakterének értéke megegyezik a zárójelben és idézőjelben a csillag előtt található karakter sorozattal. A csillag tulajdonképpen azt jelenti, hogy a helyén bármilyen karakterek is állhatnak. A meghatározó az első karakterek azonossága.
Ha a válogatást több táblázat mezői alapján végezzük, úgy a WHERE után meg kell adni azt, hogy a logikai feltételben szereplő mezők melyik relációhoz tartoznak.
SELECT TULAJD_SZ_SZ, NÉV, HRSZ FROM INGATLAN, TULAJDONOS WHERE INGATLAN.TULAJD_SZ_SZ = TULAJDONOS.TULAJD_SZ_SZ AND INGATLAN.FORG_ÉRTÉK < = 800 000
Ezt úgy adjuk meg, hogy a mező név előtt leírjuk a reláció nevét, majd egy pontot. Sem a pont előtt sem utána nincs szükség szóközre.
A kérdésre adott választ az alábbi reláció tartalmazza.
TULAJD_SZ_SZ NÉV HRSZ 1 440323 0205 TAMÁS KÁROLY 2060 2 710127 1011 KUTI JULIA 1510
Ha egy ilyen több táblázatra alapított kérdést gyakran akarunk használni, úgy célszerű lehet ideiglenes összekapcsolásuk a VIEW operátor segítségével.
CREATE VIEW OLCSO AS SELECT TULAJD_SZ_SZ, NÉV, HRSZ FROM INGATLAN, TULAJDONOS WHERE INGATLAN.TULAJD_SZ_SZ = TULAJDONOS.TULAJD_SZ_SZ AND INGATLAN.FORG_ÉRTEK < = 800 000
Amint látjuk, ebben az esetben az ideiglenes összekapcsolást külön névvel kell ellátni, esetünkben ez OLCSÓ, és egy AS hasonlítószó után teljes egészében le kell írni. A CREATE VIEW utasítás nem szolgáltat közvetlenül táblázatot, azt a megadott név, esetünkben OLCSÓ, hívásával lehet előállítani. Amennyiben már nincs szükségünk a továbbiakban az ideiglenes összekapcsolásra, úgy a DROP VIEW OLCSÓ utasítással azt megszüntetjük.
Mielőtt egy táblázatot föl tudunk tölteni adatokkal, meg kell tervezni a táblázat alakját. Erre szolgál a
CREATE TABLE INGATLAN (KÖZSÉG CHAR (16) HRSZ NUMBER (4) FORG_ÉRTÉK NUMBER (8) TULAJD_SZ_SZ CHAR (12))
kifejezés.
Megadjuk a táblázat elnevezését, az oszlopok elnevezését, valamint azt, hogy az oszlopokban milyen típust és hány helyértéket kívánunk biztosítani. Ha a táblázat fejléce elkészült, úgy soronként az alábbi kifejezéssel tudjuk feltölteni.
INSERT INTO INGATLAN VALUES ('ABASÁR', 1618, 820 000, '2_501112_1002')
Gyakran előfordul, hogy valamely mező tartalma megváltozik. Például esetünkben egy telek forgalmi értéke. Természetesen ebben az esetben nem kell az egész adatbázist, vagy a mezőt tartalmazó egész relációt átalakítanunk, hanem lehetőségünk van, amint ezt az alábbi példa mutatja, egy mezőérték megváltoztatására is.
UPDATE INGATLAN SET FORG_ÉRTÉK = 550 000 WHERE KOZSEG = 'HEVES' AND HRSZ = 2060
Az elmondottakon kívül még nagyon sok rugalmas utasítási lehetőség áll a nyelvben rendelkezésünkre, például új oszlopokat fűzhetünk egy táblázathoz, rendezhetjük a relációt valamely mező tartalma szerint stb. A néhány kiragadott példa csak azt az alaphozzáférési lehetőséget szeretné illusztrálni, mely a relációs adatbázisok kezelését egyszerűvé és hatékonnyá teszi.
Gyakran előfordul az is, hogy kérdéseinkkel az adatbázisból valamely földolgozó program számára szeretnénk bemenő adatokat szolgáltatni. Mivel a legtöbb programnyelv nem értelmezi az adatbázis lekérdezés utasításait, ezért a programban elhelyezett SQL utasításokat először egy előfordító programmal le kell fordítattni, azaz a komplett programhoz meghívunk egy olyan elő compailert, mely az SQL utasításokat a programnyelv számára érthetővé teszi. Ezután kerülhet sor az előfordított program végleges fordítására és futtatására.
Számunkra sokkal érdekesebb az a már említett eset, amikor a relációs adatbázist a földrajzi információs rendszer szoftverből kívánjuk kezelni. Annak a feltétele, hogy ez eredményesen valósulhasson meg az hogy létezzen program interface a két rendszer között.
Mint már említettük a 80-as évek végétől az ARC/INFO programrendszer, és több relációs adatbáziskezelő rendszer, köztük az ORACLE és az INGRES számára készül, illetve készült ilyen adat interface. Ez azt jelenti, hogy a földrajzi információs rendszer szoftverből az adott adatbáziskezelő rendszerek saját utasításaival, tehát az ORACLE esetében az SQL-el, az INGRES esetében a QUEL-el végezhetjük a lekérdezést. Természetesen arra is lehetőségünk van, hogy a FIR macronyelvébe a kérdéses utasításokkal definiált lekérdezéseket beiktatva macro utasítás csoportokat készítsünk.
A relációs adatbázisok és FIR szoftverek összekapcsolási lehetősége azért igen jelentős, mivel így a már régebben létrehozott alfanumerikus adatbankokat minden külön fáradtság és ráfordítás nélkül összekapcsolhatjuk az újonan létesülő térbeli adatokkal.
Az objektum orientált adatbázis modell
Az első Gothic nevű kereskedelmi, objektum orientált adatbázis kezelő rendszer, melyet az ADE nevű GIS fejlesztői környezet céljaira hozott létre a Laser-Scan, cég 1995-ben jelent meg a piacon. Az ADE rendszer architektúrájával-filozófiájával még foglalkozunk a későbbiekben. Egyelőre csak azért utaltunk erre a konkrét termékre, hogy világossá tegyük: az objektum orientált adatbázisok csak napjainkban kezdenek átlépni a kísérleti műhelyekből a gyakorlatba, s még inkább igaz ez a GIS-ben történő alkalmazásukra, mivel az objektum orientáltnak meghirdetett GIS szoftverek az ADE megjelenéséig kizárólag relációs illetve hierarchikus modellű adatbázis kezelő rendszereket használtak.
Az objektum orientált adatbázisok az objektum orientáltság elveit terjesztik ki az adatok tárolására és kezelésére.
Az objektum orientált eljárás tulajdonképpen mint programozási elv jelent meg olyan programozási nyelvekben mint a Simula, C++, Flavors, Smalltalk-80, Eiffel, stb. A módszer teljes erejének kibontakozásához arra is szükség volt, hogy maga az adatbázis is objektum orientált elvek alapján szerveződjön. Az ezt a célt szolgáló fejlesztések olyan adatbáziskezelő nyelvek és hátterükben álló adatbáziskezelő rendszerek kialakulásához vezettek pint pld. a GemStone és a SIM. Már itt meg kell ugyanakkor jegyeznünk, hogy az objektum orientált adatbáziskezelő rendszerekkel szerzett tapasztalatok még igen szerények a relációs adatbázis kezelő rendszerekkel összehasonlítva és ez az oka, hogy a nagy szoftver gyártók egyelőre még idegenkednek az új adatbázis tipusra való átálástól. Ezzel magyarázható, hogy amint azt már említettük, még az objektum orientált GIS szofverekek is rendszerint hagyományos adatbázisukban tárolják az adatokat.
Az objektum orientált módszer (object oriented approach) négy alapvető tulajdonsággal rendelkezik.
1. A 'becsomagolás' (encapsulation).
Ez a fogalom azt jelenti, hogy a módszer az elemi objektumot akár csak az elemi objektumokból létrejövő csoportokat (részhalmazokat) és osztályokat (halmazokat) mint adatok és műveletek együttesét definiálja. A 1.19 ábrán a becsomagolás eredményeképen létrejövő objektum fogalmat illusztráltuk.
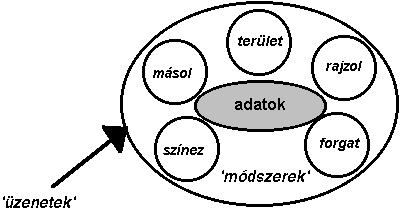
1.19 ábra - adtok és eljárások becsomagolása az objektum orientált adatmodellben
A módszer sajátos szóhasználatában a műveletek illetve eljárások 'módszerek' (methods) nevet kaptak, míg a műveleteket kiváltó címzett utasításokat illetve eljárás hívásokatokat 'üzeneteknek' (messages) hívják. Az üzenet megkeresi a címben szereplő objektumot mely módszerei a felkérés hatására müködésbe lépnek és szükség esetén új üzenetet küldenek egy másik objektumhoz stb. A folyamat mindaddig folytatódik míg a komplex művelet végre nem hajtódott.
Mivel azonban valamennyi elemi objektum (instance) gyakran azonos módszerekkel történő becsomagolása fölöslegesen megduzzasztaná a programot az objektum orientált nyelvek a halmaz elméletből kölcsönzött absztrakt hierarhikus adattipusokba szervezik az elemi objektumokat. Ezek az együttesek: az osztály (class), csoportok (subclasses) és végül maguk az elemek (instances).
2. Az öröklődés (inheritance).
Az öröklődés azt jelenti, hogy a magasabb hierarchia szinthez kapcsolt módszerek és adatok öröklődnek az alsóbb szinteken, hacsak valamely elemhez nem kapcsolunk egy azonos nevű módszert Ez utóbbi esetben ugyanis az elemhez címzett és a kérdéses magasabb szinten is definiált módszert kezdeményező üzenet hatására mindég az alacsonyabb szinten újra definiált módszer lép akcióba. Az öröklődés nem csak egy 'őstől' de több őstől is lehetséges. Ez az úgy nevezett többszörös öröklődés.
A közös információ felhasználásának az öröklődéstől eltérő módszerét választották az úgy nevezett prototípus (prototype) rendszerek. Ezek a rendszerek nem különböztetik meg az osztályt és a az elemet, azaz nem alkalmazzák a hierarchiát. Bármely objektumot választhatunk prototípusnak. Ha a kiválasztás megtörtént a többi objektumot összehasonlítjuk a kiválasztott prototípussal és az azonos tulajdonságaikat delegáljuk a prototípusban már tárolt tulajdonságokhoz, az eltérő tulajdonságokat pedig objektumonként tároljuk. A hierarchikus és a prototípus szemlélet gondolati különbsége abban áll, hogy az előbbi előzetesen végzi el az absztrakciót az osztály hierarchia kialakításakor még az előtt, hogy az egyedi objektum elemek installálásra kerülnének, az utóbbi az installált konkrét objektumból kiindulva végzi a generalizálást meghatározva a közös illetve változó elemeket.
3. Az objektum azonosság (object identity).
Ez a fogalom azt jelenti, hogy bármilyen transzformációnak is van az objektum alávetve, neve nem változhat meg.
4. A polimorfizmus (polymorphism).
Magyarra többalakúságnak fordíthatnánk, arra a hasznos tulajdonságra utal, hogy az objektum orientált rendszerben egy és ugyanaz az utasítás részleteiben különböző műveleteket eredményezhet attól függően, hogy melyik objektumnak címezzük. Ez a jellemző tulajdonképpen következménye a becsomagolásnak, mivel a konkrét műveletet (módszert) az objektum tartalmazza. Ha tehát például kiadjuk a draw utasítást és megcímezünk vele egy kört tároló objektumot, akkor az utasítás eredményeképpen egy kör jelenik meg képernyőn, ha azonban a cím egy tó határait tartalmazza, úgy ugyanazzal az utasítással a tó alaprajzát készítettük el. Nem igényel külön magyarázatot, hogy a polimorfizmus nagyon előnyös abból a szempontból, hogy az objektum megváltozása nem vonja maga után a program megváltoztatását.
Az objektum orientált módszer megjelenésekor a programozási munka egyszerűsítést, részekre bontását, rövidebb és áttekinthetőbb programok létrehozását tűzte ki céljául. A fejlődés azonban azt eredményezte, hogy e stílus lehetőségei meghaladták az eredeti célokat. E lehetőségek elsősorban az összetett adatstruktúrák modellezésében jelentkeznek. Azok az előnyök azonban melyeket az objektum orientált rendszer nyújt a rendszer konzisztenciája, egyszerű bővíthetősége, alkalmazásra alakíthatósága szempontjából akkor is indokolja alkalmazását, ha a rendszer koncepcionális adatmodelljét egyszerű objektumok alkotják.
· a következő rész az analóg és digitális térinformatikai rendszerek körvonalait vázolja fel,
· visszatérhet az előző részhez is,
· vagy a tartalomjegyzékhez.
Megjegyzéseit E-mail-en várja a szerző: Dr Sárközy Ferenc